DB Performance
Overview
DBのパフォーマンスについてのセクション。
データベースのパフォーマンスを決める主な要因は、ディスクI/Oの分散、SQLにおける結合(正規化)、そしてインデックスと統計情報。
- ディスクI/Oの分散
- SQLにおける結合(正規化)、そしてインデックスと統計情報
インデックス以外のチューニング手段には、パーティション・ヒント句・オンメモリ化・パラレルクエリがある。
データベース設計というと、論理設計にのみ目を奪われがちですが、それでは十分なパフォーマンスを確保するには不十分。
データベースにおけるパフォーマンスの設計には、DBMS の内部アーキテクチャに踏み込む物理レベルの知識が必要になる。
パフォーマンスを測る 2つの指標
システムの世界ではパフォーマンスは2つの指標(メトリクス)によって測られる。
- 処理時間(プロセスタイム)や応答時間(レスポンスタイム)と呼ばれる指標
- スループット(Throughput)速度と同じ概念
スループットがなぜ重要なのか
スループットが性能において重要なのは、これがシステムの「リソースキャパシティ」を決定する要因だから。
と言うのは、スループットの高いシステムであるほど、「CPUやメモリといったハードウェアリソースがたくさん必要になること」を意味しているから。
1つでも処理を実行すれば、システムはリソースを消費する。
そのため、同時に実行される処理が増えれば増えるほど、用意すべき物理リソースが増えていく。
処理の種類によっても必要なリソースの種類や量は変わってくるのですが、話を単純化して「どの処理も同じぐらいのリソースを消費する」とすれば、同時実行される処理数に比例して、必要なリソース量も増えるということになります。 平たく言うと、「同時に実行するユーザ数が増えれば、必要になる物理リソースも増える」ということ。
同時実行処理数が増えるほど用意すべきリソースも増えどれか1つのリソースでも頭打ちになった時点で、性能の劣化が始まる。
すなわち、レスポンスタイムが上昇を始め、反対にスループットが下がり始めます。
このとき最初に頭打ちになるリソースを「ボトルネックポイント(Bottle neck Point)」、略して「ボトルネック」と呼ぶ。
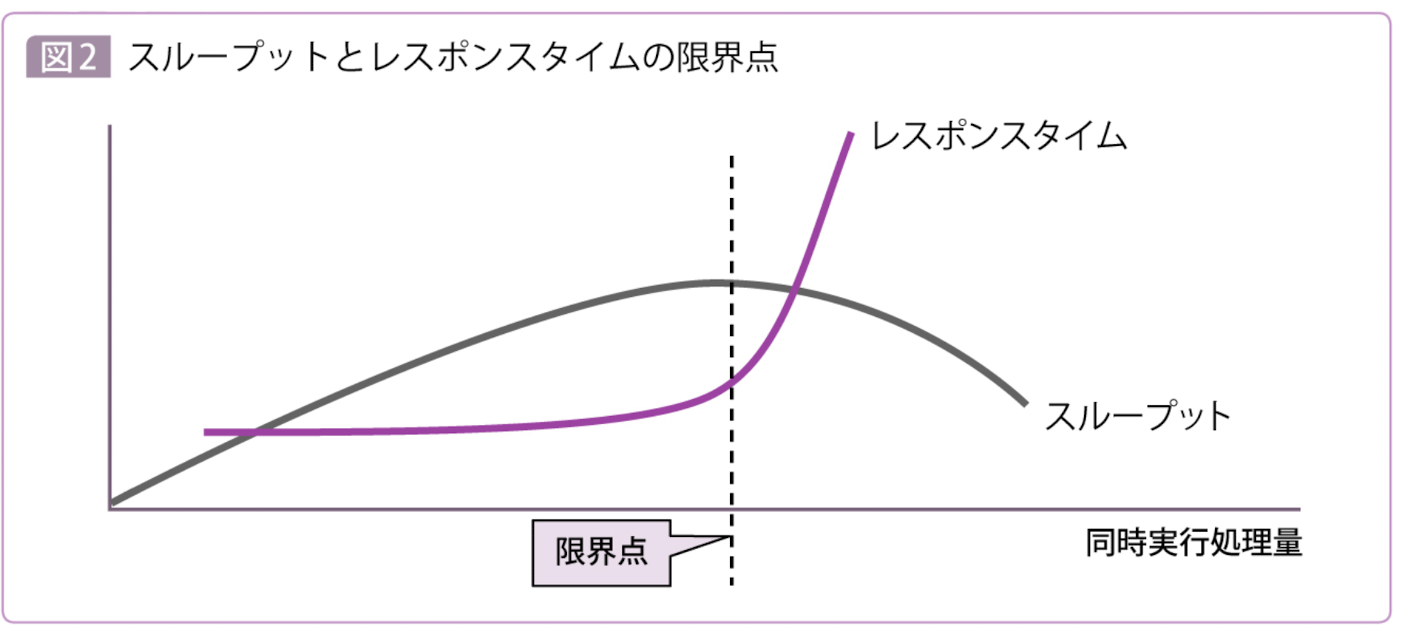
これが意味することは、**「システムは、同時に実行される処理量がもっとも大きくなるタイミングを想定してリソースを用意しておかなければ、ピーク時に極端な遅延を引き起こすことになってしまう」**ということ。
このスループットとレスポンスタイムが極端な劣化を始める処理量を、「限界点(Breaking Point)」と呼ぶ。
ビークを想定したリソースを確保することを「サイジング(Sizing)」やキャパシティプランニング(Capacity Planning)と呼ぶ。
※システムの要件定義段階においてキーとなるタスク。
突発アクセス対策
ピークが不安定かつ最大値を予測しにくいケースがある。
ピーク時に必要なリソースを用意してしまうと、逆に普段はリソースが遊んでしまってムダになる。
これらの対策としてクラウドがある。クラウドは仮想化をベースにリソース量を柔軟に変動させられる技術。スケールアップもスケールアウトも容易。
データベースはなぜボトルネックになるのか
システムにおいてもっともボトルネックになるところ
- 扱うデータ量がもっとも多い
- リソース増加による解決が難しい
- クラウドだと動的にリソースを増減できるため有効
しかしDBのボトルネックはCPUやメモリではなくストレージ。
すなわち大抵の場合はハードディスク。
そして、ストレージというのはスケールアウトが困難なコンポーネント。
これは、データベースが基本的に「Active-StandBy構成」か、シェアードディスクによる「Active-Active構成」しかとれないため。
ストレージも含めてスケールアウト可能なのは、シェアードナッシングのケースだけ
しかし、シェアードナッシングを採用できる条件は限られている
そのような制限があることから、データベースの世界では伝統的にチューニングの技術が発達してきた。
「チューニング」とは、すなわちアプリケーションを効率化することで、同量のリソースにおいてもパフォーマンスを向上させる技術のこと。
データベースに限って言えば「どうやってSQLを速くするか」ということとほぼ同義。
リソース追加によるパフォーマンス問題の解決が難しいため、いかにして与えられたリソースの範囲内でやりくりするか、ということが重要になった。
例えるなら、決められた予算内で家計をやりくりする主婦みたいなもの。
DBの処理順序
SQL文のパフォーマンスを考える場合は、DBが内部でどの順序でSQLを処理しているかを見ていく必要がある。
DBがSQL文を実行する内部プロセス順序
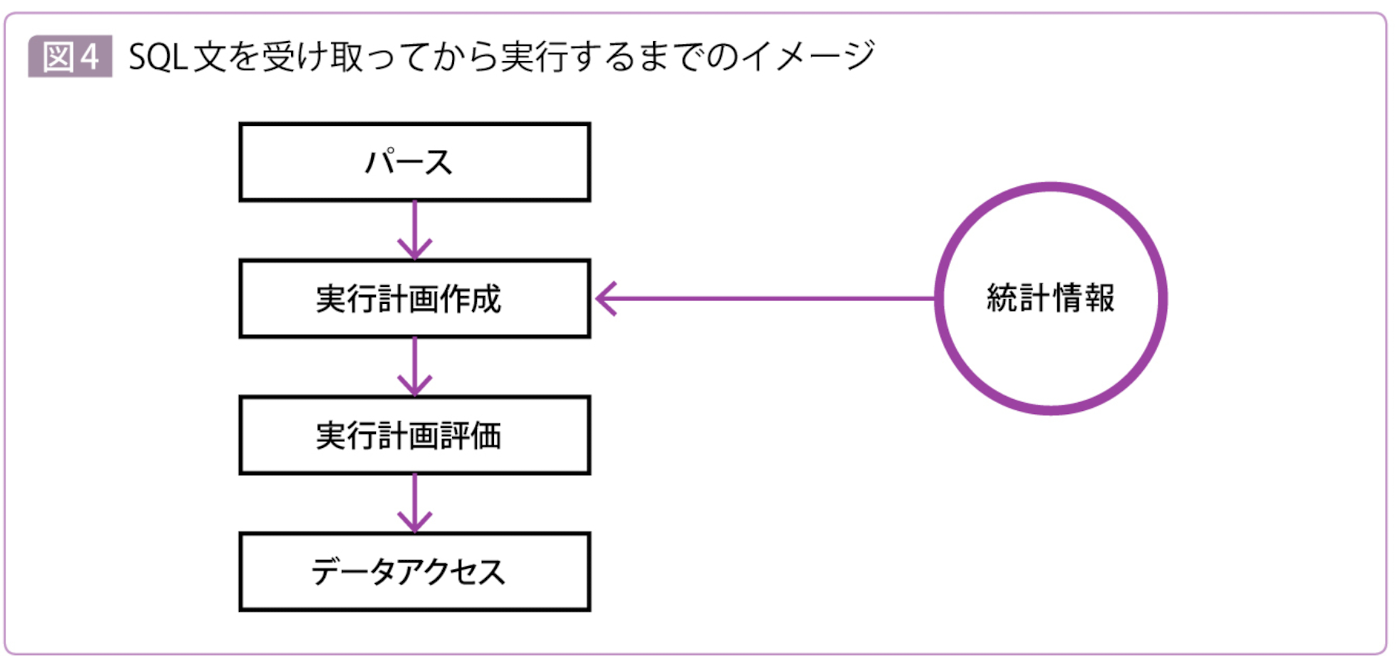
- 構文エラーがないか確認するparse
- SQL文から実行計画(Execution Plan)を立て、実行計画を決めるプログラムをオプティマイザー(Optimizer)と呼ぶ
- この「実行計画を立てる」というプロセスをデータベース自身が行うのは、リレーショナルデータベースの大きな特徴。C言語やJavaといったプログラミング言語を使ってプログラムを作る際には、このようなプロセスは存在しない。
- その理由は、プログラミング言語で作られるプログラムでは、プログラマ自身(人間)が、どうやってデータにアクセスするかまでプログラムの中に書き込んでいる(コーディングしている)ため。
- 実際、プログラミングの経験がある方ならばわかると思いますが、データにアクセスする処理を記述する際は、「この場所に置いてあるファイルを開く」とか「ファイルを1行ずつループして先頭行から最終行まで読み込む」といったレベルまですべてコーディングする必要がある。
- だが、SQLはどうやってそのデータを見つけ出すかはSQLに一切書かれていない
- そのためたびたび宣言型言語と呼ばれる
オプティマイザーが参考にする統計情報
統計情報はDB内部ではテーブルに保存されており、MySQL では show table status; または show index from テーブル名 で見ることが可能。
実行計画を表示する
SQL文の実行計画を取得する方法はSQL文の前に EXPLAIN をつけるだけ
mysql> > EXPLAIN select * from t1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.06 sec)
- rows
- アクセスしたレコードの行数
- type
- ALL: フルスキャン
- range: レンジスキャン
- ref: レンジスキャン
- possible_keys
- インデックスを使っていることを表す
- keys
- インデックスを使っていることを表す
テーブルに対するアクセス方法
テーブルへのアクセス方法は2つある。
- フルスキャン(ALL)
- レンジスキャン(range)
レンジスキャン
レンジスキャンをするためにはインデックス(索引)が必須。
インデックスがないカラムを WHERE 句に入れてもレンジスキャンにはならない
長時間クエリの実行対策
パフォーマンスチューニングは必須だが、まずはタイムアウトを設定しておく。
フルテーブルスキャンはしない
SELECT文であるレコードを取得したいときに、対象のテーブルを全件検索してしまっている検索方法
LIKE * などをするとフルテーブルスキャンをしてしまうため注意が必要!
フルテーブルスキャンをしてしまう構文
MySQLだとSELECT Queryの前に EXPLAIN をつけることで確認ができる。
| type | 検索方法 |
|---|---|
| ALL | フルスキャン、全件検索 |
| index | フルインデックススキャン |
| const | 主キーやユニークキーを使って検索 |
| eq_ref | ↑と類似。表結合しているものに使われると表示される |
| ref | ユニークじゃないインデックスを使って検索 |
| range | インデックスを使って検索 |
問題なのが前述の「ALL」と「index」