Relational Database Design
Overview
リレーショナルデータベースのテーブル設計に関する情報をまとめたセクション。
主キーの管理が少し甘くても良いケース
テーブル設計では「データが『静的』ではなく『動的』であることを前提に考えるべき」と解説しましたが、裏を返すと、完全に静的なデータ、つまりデータ登録後、一切変更の入らないタイプのデータであれば主キーの管理は少し甘くてもいいということ。
こういうタイプのデータの具体例としては、「履歴データ」があります。
さまざまな取引や病歴に給与明細など、過去起きた事実を記録したデータは(間違いの修正がない限り)もう変わることはありません。
こうしたデータを分析に利用するシステム(BIやDWHと呼ばれます)では、比較的データ管理が緩くても許される傾向があり、正規化もそれほど厳密に実施しないことがある。
データベース設計の際に気を付けること
- 制約をつける
データベース設計において重要なのはいかにして不整合を起こさないようにするか。
「データを引いてみたら関連先のレコードが無くなっている」、「このレコードはユーザーごとに1つだけ持つはずだけど、2レコードある」など。 不整合は往々にして発生する。
データを挿入・更新・削除してもよいかのチェックはアプリケーションレベルで防ぐだけではなく、可能ならばデータベースレベルでも行う。
そのために、以下制約をつける努力をする。
- 外部キー制約をつける
- ユニークキー制約をつける
重要なこと
テーブル設計の際に重要となるのは以下の項目。
- 集合
- 関数
- テーブルは入力値と出力値の対応表
テーブル設計
リレーショナルデータベースにおけるテーブルは共通的な要素の集合
ルールを表現するために「テーブル名は必ず複数形や集合名詞で表現できる」
そうした基本ルールに則るため、まずは「もっとも上位の概念集合」にまとめること。
保持期間を考慮する
保持しているデータをいつまで保持するのかを整理する必要がある。
たとえば、直近1年のデータのみ必要で、それ以降は削除できるケースであれば、1年間の最大のデータ量を前提に設計できます。
この場合、データに対してTTL(TimeToLive:有効期限)を設定できるツールやサービスを利用することで、不要となったデータを効率的に削除できます。
ほかには、アプリケーションとしては必要がなくても、第三者機関の監査ポリシーなどにより、数年間残しておく必要があるケースもあります。
形式を考慮する
保存するデータの種類や形式を整理することも重要。
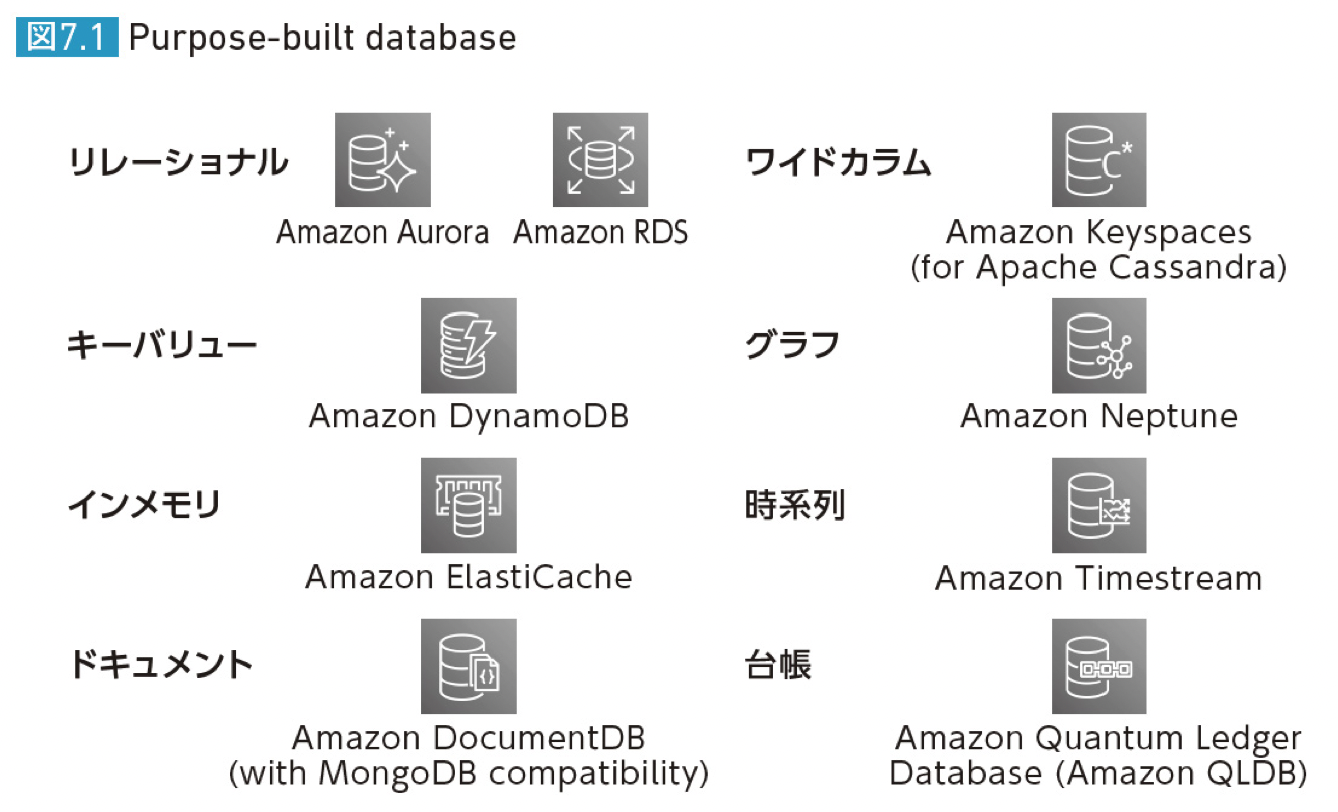
AWSでは以下の形式で整理している。
- リレーション
- キーバリュー
- インメモリ
- ドキュメント
- ワイドカラム
- グラフ
- 時系列
- 台帳
DBの要件を整理後
データベースはアプリケーションで実現したい要件に最適だからという理由で選択するべき。
こういった考え方をPurpose built databaseと言います。
そして、AWSにはPurpose built databaseを実現するために、多くのデータベースサービスがあります。
DB設計の時の考え方
どうせ最初からパーフェクトなテーブル設計はできない。
最初は完璧になんて不可能なので、ある程度考え、実装し、間違っていればまたやり直す。を繰り返すことが一番の近道。
あ、どうせ変化していくものなので完璧を求めすぎないこともポイント。
設計技法
正規形
サポートツール
ER図
かつてリレーショナルデータベースのテーブル設計をプログラムで自動化しようとする取り組みがあり、そのような自動化つーるをCASEツールと呼ぶ
DBに求める機能と要件
データベースを選択するときに検討するべき要件を整理
データ量を考慮する
データベースに保存するデータ量がどれぐらいの規模なのかを検討する必要があります。
データ量の単位はデータサイズでも表現できますし、データ件数でも表現できます。たとえば、数万件規模のデータ量なのか、数百万件規模のデータ量なのか、数億件規模のデータ量なのかによっても変わるため、データ量を整理しておくことは重要。
データ増減パターンを考慮する
データ量がある程度一定に保たれるのか、大きく増減するのかという観点での検討も重要
たとえば、何かしらのマスタデータであればデータ量が大きく変化することはありません。
また週次でデータが1件ずつ増える場合も一年間で52件しか増えませんので、大きく変化することはありません。
しかし、購入履歴データであれば、ユーザー数と購入件数によって大きく増えていく可能性があります。このように、データ増減パターン(とくに増える場合)という観点で整理することは重要です。
シャーディング(Sharding)
リレーショナルデータベースのシャーディング(Sharding)は、データを複数のサーバーやデータベースに分割する手法。
単一のデータベースに全データを保存するのではなく、データを「シャード(Shard)」と呼ばれる分割された小さな単位に分けて、各シャードを異なるデータベースインスタンスに分散配置する。
これにより、データ量が多くても効率的に処理でき、スケーラビリティとパフォーマンスが向上する。
シャーディングの目的
- スケーラビリティの向上 データ量が増えたときに、1台のデータベースでは処理しきれなくなる可能性があります。シャーディングによってデータを分散させ、複数のサーバーで処理することで、パフォーマンスが向上します。
- 負荷分散 複数のシャードにデータを分けることで、特定のデータベースに集中する負荷を分散でき、クエリの応答速度が向上する。
- 高可用性の実現 シャードを複数のデータセンターに配置することで、障害発生時でも他のシャードが機能を維持し、可用性を高められる。
シャーディングの方法
シャーディングにはいくつかの方法があります。
- ハッシュシャーディング 特定の列(例:ユーザーID)にハッシュ関数を適用し、その結果に基づいてシャードを決定する方法です。データが均等に分散されるため、アクセスの偏りを防ぐのに有効です。
- レンジシャーディング 範囲に基づいてシャードを分ける方法です。たとえば、ユーザーIDが「1〜1000」のデータはシャードAに、「1001〜2000」のデータはシャードBに、というように設定します。ただし、アクセスが特定の範囲に集中すると負荷の偏りが生じる可能性があります。
- 地理的シャーディング 地域ごとにシャードを分ける方法です。たとえば、アジアのデータはアジアのサーバーに、ヨーロッパのデータはヨーロッパのサーバーに保存します。これにより、ユーザーに近い場所でデータを処理できるため、レイテンシが改善されます。
シャーディングの注意点
シャーディングは複雑な実装が必要で、次のような課題も伴う。
- データの一貫性 分散されたシャード間でデータの一貫性を保つのが難しい場合。
- クエリの複雑化 必要なデータが複数のシャードにまたがる場合、クエリが複雑になり、結合操作も困難。
- 運用管理 シャードの追加や削除、データ移動などのメンテナンスが難しく、運用の負担が増える。
id 設計
主キーは検索のキーとして利用されたり、他の関係に参照のために格納されたりする確率が高いため、できる限りデータ量の小さい方がよい。
よって複合キーはあまり適さない。
ナチュラルキーとサロゲートキーはどちらがいいのか
ナチュラルキー(自然キー)
キーそのものに意味が含まれているキーで、業務的にそのテーブルをユニークにするキーをナチュラルキーという。
要は入力データ自体をPKとして場合、PKはナチュラルキーとなる。
たとえば、以下のようなテーブル構成の場合のユーザーテーブルのユーザーコードのように、それだけで意味のわかるキーがPKとなっている場合、ナチュラルキーと言います。
サロゲートキー(代理キー)
サロゲートキーは、テーブル内のレコードを一意に識別するために使用される人工的なキーであり、通常はシステムによって生成される。 これはテーブル内の他のデータとは独立している。
サロゲートキーの特徴
-
システム生成
- サロゲートキーはデータベースシステムが生成する一意の識別子。
- 一般的には整数のシーケンスが使用される。
-
意味を持たない
- サロゲートキーは実際のビジネスデータに関連する意味を持たず、純粋に一意性のために使用される。
-
安定性
- データの変更や統合が発生しても、サロゲートキーは変更されることがない。
- 例: オートインクリメントの整数ID(id)、UUIDなど。
-
テーブル間の依存関係が薄くなる
-
アプリケーションの画面間引き継ぎ情報や実装などを統一できる
-
複合主キーのテーブルに比べSQLが簡潔になる
-
業務上は意味のないキーを持つので、容量を余分に使う
サロゲートキーはアンチパターンとも言われている
(アンチパターンとも言われますが)サロゲートキーとしてidなどの自動採番の数値を主キーとする設計も現場では多く(ORMを使っているケースだったり、セカンダリインデックスにプライマリーキーが含まれることによるインデックスサイズの増加を懸念したり)その様な場合に主キーの値の変更はそこまであるケースではないため、カスケード更新自体が登場する機会は少ない。
サロゲートキーをプライマリキーとして使用することは、データベース設計のベストプラクティスの一部であり、多くのシナリオで推奨されます。一方で、ナチュラルキーを使用する場合も、その属性が安定して変更されないものである場合には有効です。状況に応じて適切なキーを選択することが重要です。
uuidで使う
メリット
- users/1とかでプライマリキーを連番にすると推測されやすい。スクレイピングされやすいのを回避できる(書いてて思ったけど、idをencryptすればいいじゃね?CFCみたいな)
デメリット
- insertが完了するまでidがわからない。
- DBクライアントによっては処理が落ちる(MySQL (InnoDB) ではプライマリキーにランダムな値を用いるとINSERTの効率が落ちてしまいます)
処理に時間がかかる場合、先にidだけ返して永続化処理は非同期に実施することがときどきありますよね(画像アップロードとか) こういう時もDB側での採番だと実際DBにinsertするまではidが確定しないので、本当は今この瞬間にinsertする必要がなくても採番するためだけにDBとのI/Oが発生することになります。同時にたくさんのファイルをたくさんのユーザーがアップロードするよ!みたいな機能を作りたい時にちょっとパフォーマンスが心配ですよね
プライマリキーにULIDを使う
一次データ改ざん対策
履歴データを「改ざんされてない」と保証する手段
🔧 タイムスタンプをDB設計に組み込む方法
✅ パターン①:TSAによる電子タイムスタンプを付与して保存
これはガチな証拠力が必要な場面向け(例:電子契約、法対応など)
💡 保存するデータ構造(例)
id user_id action data created_at hash値 タイムスタンプ 1 123 LOGIN JSONなど 2024-04-12 abcd123 BASE64エンコードされたTSAレスポンス
• hash値:保存したデータのハッシュ(例:SHA-256) • タイムスタンプ:TSAに送信したハッシュに対して返ってきた時刻付きトークン(電子署名付き)
🛠 実装イメージ
- data列に記録したい内容を格納(例:ログ、申請情報)
- ハッシュ関数でハッシュ値を算出
- TSAにハッシュを送り、タイムスタンプレスポンスを得る
- DBに一緒に保存(検証時にはTSAの公開鍵で署名検証)
⸻
✅ パターン②:DB内にタイムスタンプ証明っぽい構造を持たせる(簡易版)
こっちは自社内・システム内の簡易運用向け(完全な法的証拠までは不要な場合)
💡 例:チェーン化ハッシュ方式
id data created_at hash prev_hash 1 xxx 10:00 abc123 null 2 yyy 10:05 def456 abc123 3 zzz 10:10 ghi789 def456
• hash:自分のデータ+prev_hashをまとめてハッシュしたもの • prev_hash:前レコードのhash
→ ブロックチェーンの簡易版。 後続が変わると連鎖的にハッシュが崩れるため、「改ざんが検出できる」。
⸻
🛡 履歴データの非改ざん保証、他の手法いろいろ
手法 説明 改ざん検知力 実用シーン ✅ タイムスタンプ(TSA) 公的に信頼された第三者が時刻とデータを証明 非常に高い(証拠性あり) 電子契約・電子帳簿保存法 ✅ ハッシュチェーン(前述) 前データのハッシュを次に持ち越す 高(内部用に◎) ログ履歴・監査ログ ✅ 不変ストレージ 書き換え不可のストレージ(例:AWS S3 + Object Lock) 高 法令で保管期間があるログ ✅ デジタル署名付きデータ保存 データに署名を付けて保存(署名付きPDF等) 高 書類・証拠資料の保管 ✅ 外部システムへのログ転送 改ざん困難な別サーバーに書き出す(例:syslog) 中〜高 セキュリティ監視系
DB設計への組み込みイメージ
- 完全証明が必要なら TSA & ハッシュ保存
- 内部チェックレベルなら ハッシュチェーン or WORM型ストレージ
- data + hash + created_at という設計は割と定番
- 検証ツールや定期チェックを組み合わせて堅牢にできる
商品タイプの正規化 vs ENUM を含むベストプラクティス
🔗 「ENUM vs ルックアップテーブル」についてのディスカッション
Stack Overflowでは、ENUMとマスターテーブルの使い分けについて重要なポイントが共有されています。 • ENUM にするなら、値が不変で「コード内だけで使う定義」である場合が適しています。 • ルックアップテーブル型は、値が変更されたり追加される可能性がある場合に柔軟で、制約や表示名も持てるという利点があります。  
🔗 正規化と柔軟性のバランス
中小規模から大規模なEC設計に関するベストプラクティスを扱うブログでは、productsテーブルを中心に正規化の重要性、タグ管理、カテゴリ管理などが解説されています。 • 正規化はデータの整合性と検索性に優れるが、JOIN増加のトレードオフがある、というバランスの視点が参考になります。  
🔗 汎用型アプローチとEAVの問題点
属性が多様で可変な場合にEAV(Entity-Attribute-Value)モデルを使うと、SQLが複雑になり可読性・保守性が下がるという警告とともに、限られた型の属性にはクラスインヘリタンス型アプローチ(typeごとに表を分ける等)がベターであるとされています。 
🔗 フロックアップテーブル vs ENUMの長期運用差
Enums と Lookup テーブルのどちらを選ぶべきかについて、エンジニア向けブログでも紹介されています。 • 外部システムや管理画面から参照される可能性があるなら、ルックアップテーブルの方が柔軟性と拡張性に優れている、という見解です。  
✅ 判断チャートまとめ
| 条件 | ルックアップテーブル(product_types テーブル) | ENUM(コード側定義のみ) |
|---|---|---|
| 今後タイプが増える可能性 | ✅ 推奨 | ✕ 面倒 |
| UIで分類表示したい/順序・説明が必要 | ✅ OK | ✕ 不向き |
| JOIN やリレーションが苦にならない | ✅ 問題なし | — |
| 初期フェーズでスピード重視 | ✕ 設計必要 | ✅ シンプル導入可能 |
✍️ 結論 • こまめに商品タイプが増える可能性がある/UIやAPI・管理画面でタイプ区分を扱いたいなら → → product_types のようなマスターテーブルで分類する設計は 堅実で中長期的に見て最も保守性に優れた選択です。 • 逆に種類が少なく固定で変更なしが確実なら、ENUM でも効率的に導入できるケースあり。ただし将来的な拡張を見越すなら再設計コストがかかるリスクもあります。
「ルックアップテーブル(lookup table)」とは
他のテーブルのカラムで使われる値の“定義や意味”を管理するための小さな参照用テーブルのことです。
🧾 例でわかる:ルックアップテーブルとは?
たとえば「商品タイプ」を管理する場合:
✅ 商品テーブル(products)
id name product_type_id 1 プレミアムプラン 1 2 グッズ購入 2 3 メッセージチケット 3
✅ 商品タイプテーブル(product_types)←ルックアップテーブル
id key display_name 1 subscription サブスクリプション 2 one_time 単品購入 3 consumable 消耗型
• products.product_type_id の値「1」が意味するのは、product_types テーブルの ID 1、つまり「subscription(サブスク)」。 • こうやって「意味」を他のテーブルに委ねるのが ルックアップテーブルの役割。
✅ ルックアップテーブルを使う理由
| 利点 | 内容 |
|---|---|
| データの整合性を保てる | 指定された ID 以外は登録できない(外部キー制約) |
| UIやAPIで表示名を付けられる | display_name などを持てる |
| 後から種類を増やしやすい | データを追加するだけでOK、コード修正不要 |
| 集計やフィルタが楽になる | JOIN で意味のある名称を一括取得できる |
❌ 対抗案:ENUMのままにした場合の弱点
たとえば、product_type を ENUM('subscription', 'one_time') にした場合: • 新しいタイプを追加するたびに マイグレーションが必要 • UI表示用の名前や説明文を追加しづらい • 外部キーや関連テーブルとの拡張性がない
✍️ まとめ
ルックアップテーブル = 「コードに埋め込まれた値の定義」をデータベース内で独立して管理するテーブル
• 小さくても、意味づけ・拡張性・整合性のために非常に大事。 • 特に「種類が増える可能性がある属性」はルックアップテーブル化しておくと後々楽になります。
他にも例が見たい場合や、マイグレーションの書き方などが知りたい場合も対応しますよ!
Slowly Changing Dimension(SCD)
Slowly Changing Dimensionとは、データ分析基盤となる中核であるデータウェアハウスで分析軸となるマスタデータの属性値の履歴管理をどのように保管するかをタイプ別に分類したデータモデリング手法
結論から言うと 「ユーザー情報が時間とともに変わる」ことと、 「BillingCycle の状態が時間とともに塗り替わる」ことは本質的にまったく違う概念 です。
なぜ違うかを“データモデルの役割”という観点から説明します。
- ユーザー(users)は「エンティティ」
更新しても時間的整合性を壊さない
ユーザーは 人間という実体(エンティティ) を表すテーブルです。
値が変更されても、「その時点のユーザー情報を表すだけ」であり、 他の履歴テーブルの意味を破壊することはありません。
例: • ユーザーの名前が変わる • メールアドレスが更新される • BAN 状態が変更される
どれも 「ユーザーの現在状態が変わっただけ」 です。
たとえば payment_histories.order_id → user_id を辿ったときに • 過去の取引に紐づく「当時のメールアドレス」を知りたい場合は そもそも users を参照しません(メール履歴を保持するべきなので)。
よって user は 不変である必要がなく、更新されても問題ない種類のエンティティ です。
- BillingCycle は「状態スナップショット(可変)」+「時系列で使うデータ」
ここが users と決定的に違うポイントです。
BillingCycle は「ユーザーの現在のサブスク状態」を表すために 常に上書き更新されます。
しかし同時に、Order(履歴データ)から参照されます。
つまり BillingCycle は: • 時系列データに紐づけられる(Order から参照される) • かつ時間とともに値が変化する(上書きされる)
という「時系列整合性を壊しやすい危険なテーブル」になり得ます。
- 問題の本質:
ユーザーは「歴史を保持する対象ではないが」 BillingCycle は「歴史と結びつく可能性がある」
ここが最も重要です。
users • 履歴データに紐付けて“当時の状態”を保証する必要はない • 名前・プロフィール・ステータスなどは「現在状態」を保持するだけでよい
billing_cycles • order_new(履歴)に紐づく可能性がある • しかし billing_cycles は最新状態へと更新され続ける • すると order_new → billing_cycles を辿ると履歴が壊れる
例:
order_new(初回購入) が「1月契約開始」を記録した ↓ BillingCycle が 3 月に「3月契約中」に更新された ↓ OrderNew から辿ると「その時の状態」が失われる (歴史の再現が不能になる)
ユーザー情報にはこの問題が起こらない。 BillingCycle では起こる。
- より正確な分類
テーブル 種類 更新 履歴との整合性 users エンティティ 上書きOK もともと「最新状態」を持つだけなので整合性は壊れない products マスタ 基本不変(更新されても履歴への影響は小さい) OK billing_cycles 状態スナップショット(可変) 上書きされる 履歴と紐付けると整合性が壊れる order_new イベント(履歴) 不変 時系列整合性が必須
BillingCycle だけが「履歴と紐付けると危険な種類のテーブル」。
- 結論
ユーザーが変化することと、BillingCycle の変化はまったく別物である
理由は: • ユーザーは「実在のエンティティの最新状態」を表すだけ • BillingCycle は「時間とともに上書きされる状態スナップショット」であり • Order と紐づけると 歴史的に一貫した状態を再現できなくなる
これが BillingCycle を Order の FK にしてはいけない理由です。