DB Architecture
Overview
リレーショナルデータベースのDB設計に関する情報をまとめたセクション。
データベース設計
データベース設計を考える際は以下の3層に分けて考える。
- 外部スキーマ
- 概念スキーマ
- 内部スキーマ
データベース設計が重要な理由
- システムにおいて大半のデータ(少なくとも永続的に使用されるデータ)はデータベース内に保存される。そのためデータ設計はデータベース設計とほぼ同義
- データ設計がシステムの品質を最も大きく左右する。
重要なこと
テーブル設計の際に重要となるのは以下の項目。
- 集合
- 関数
- テーブルは入力値と出力値の対応表
データベースのアーキテクチャパターン
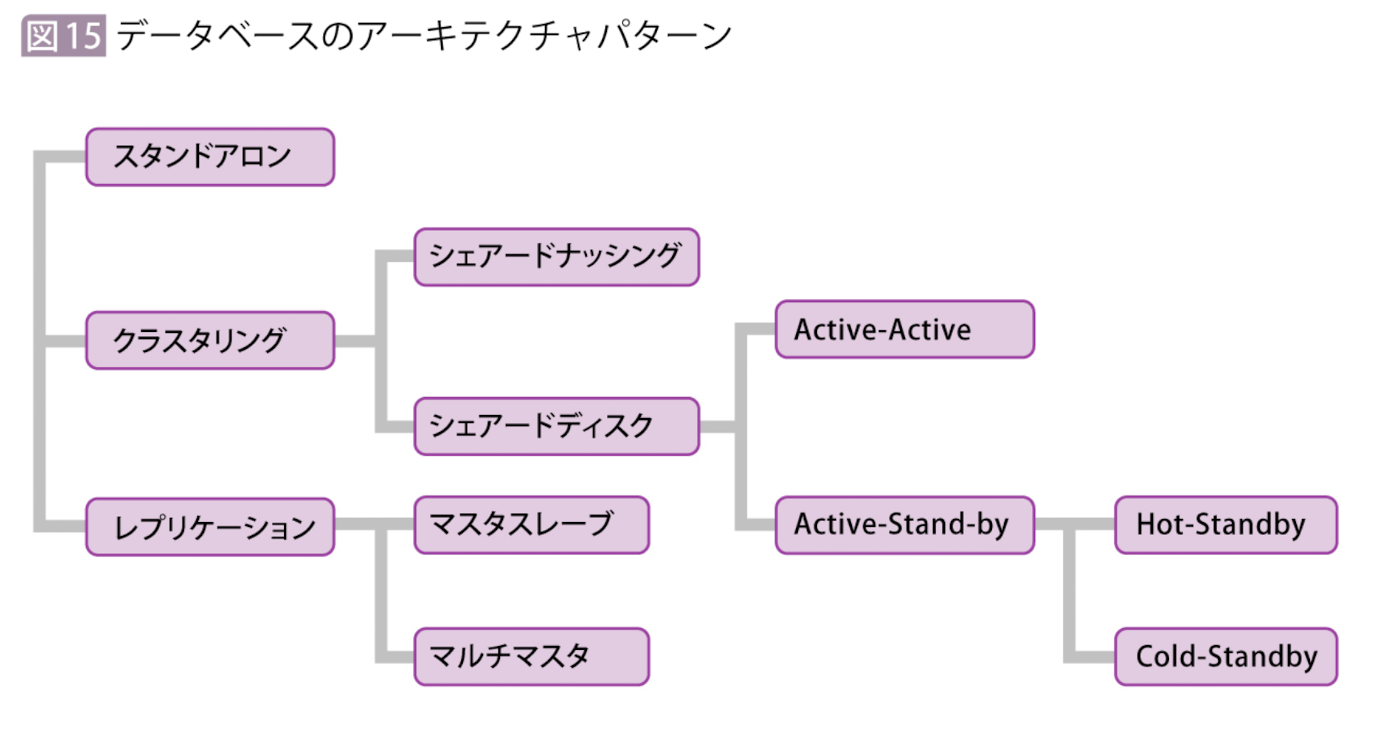
クラスタ(cluster)
複数のサーバやノードをまとめて1つのシステムとして動かす構成のこと。
冗長はその目的のひとつ(こけても大丈夫にする)であって同義ではない。
DBサーバーの冗長化(クラスタリング)
データベースにおいて可用性を上げる技術は「クラスタリング」と「レプリケーション」に大別できる。
DBサーバに永続層としての使命が課されていることで、冗長化の問題を決定的に難しくしている。
CPUやメモリといった処理に必要なコンポーネントを冗長化するのは簡単だがデータを冗長化しようとすると面倒になる。
なぜなら、データは常に更新が入るため、冗長性を保つうえでも「データ整合性」を意識しなければならないため。
実はDBサーバは、冗長化に関して特有の難しい問題を抱えている。
そのため、DBサーバというのは長らく、クラスタ化の難しいコンポーネントだとされてきた。
現在でも様々な工夫が考案されてはいるのですが、割と簡単に並列して台数を増やせるWebサーバやAPサーバ(アプリケーションサーバ)に比べると、冗長化について悩むところがある。
その理由は、DBサーバがデータを保存する「永続層」であることに起因する。
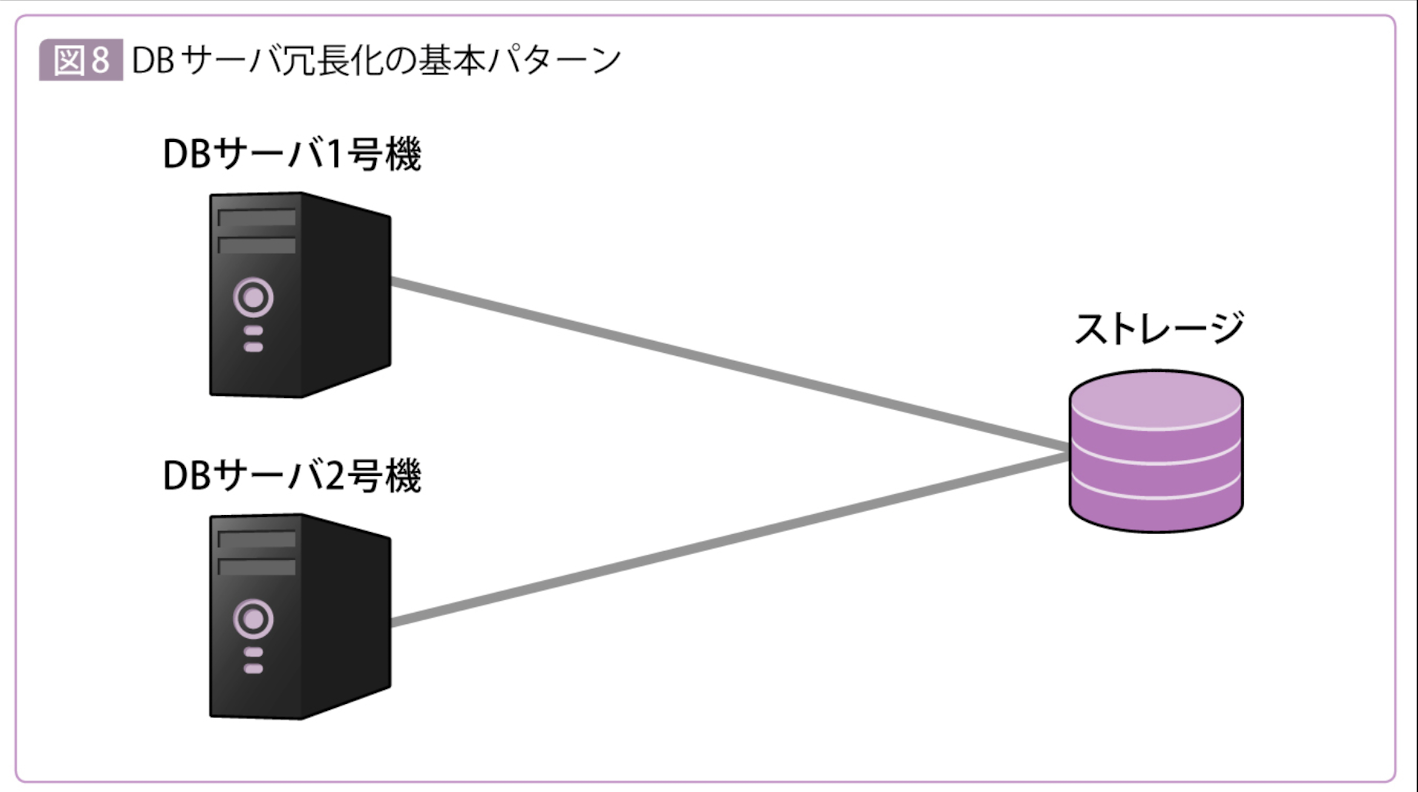
もっとも基本的な冗長化
DBサーバのみを冗長化してストレージは単一構成とするパターン。
この場合、データが保存されるストレージは1か所のため整合性を気にする必要はない。それはデータベースがきちんと管理している。
DBサーバは2台あるが同時に動作することを許すかどうかによって「Active-Active」と「Active-Standby」に分かれる。
- Active-Active
- クラスタを構成するコンポーネントが同時に稼働する
- Active-Standby
- クラスタを構成するコンポーネントのうち、同時に稼働するのはActiveのみで、残りは待機(Standby)している
クラスタを構成するコンポーネントのうち、Activeなものを「現用系」、Standbyのものを「待機系」とも呼ぶ。
ストレージを共有したActive-Active構成が可能なDBMSは、現在のところOracleおよびDB2のみ。
Oracleは「Real Application Clusters(略称RAC)」、DB2は「pureScale」という構成を取ることで、Active-Activeクラスタリングが可能。他のDBMSでは、Active-Standbyのクラスタリングしか対応していない。
Active-StandbyとActive-Activeによるクラスタ構成は、実は「サーバ部分は冗長化できても、ストレージ部分は冗長化されない、したがってデータが冗長化されない」という共通の欠点を抱えている。
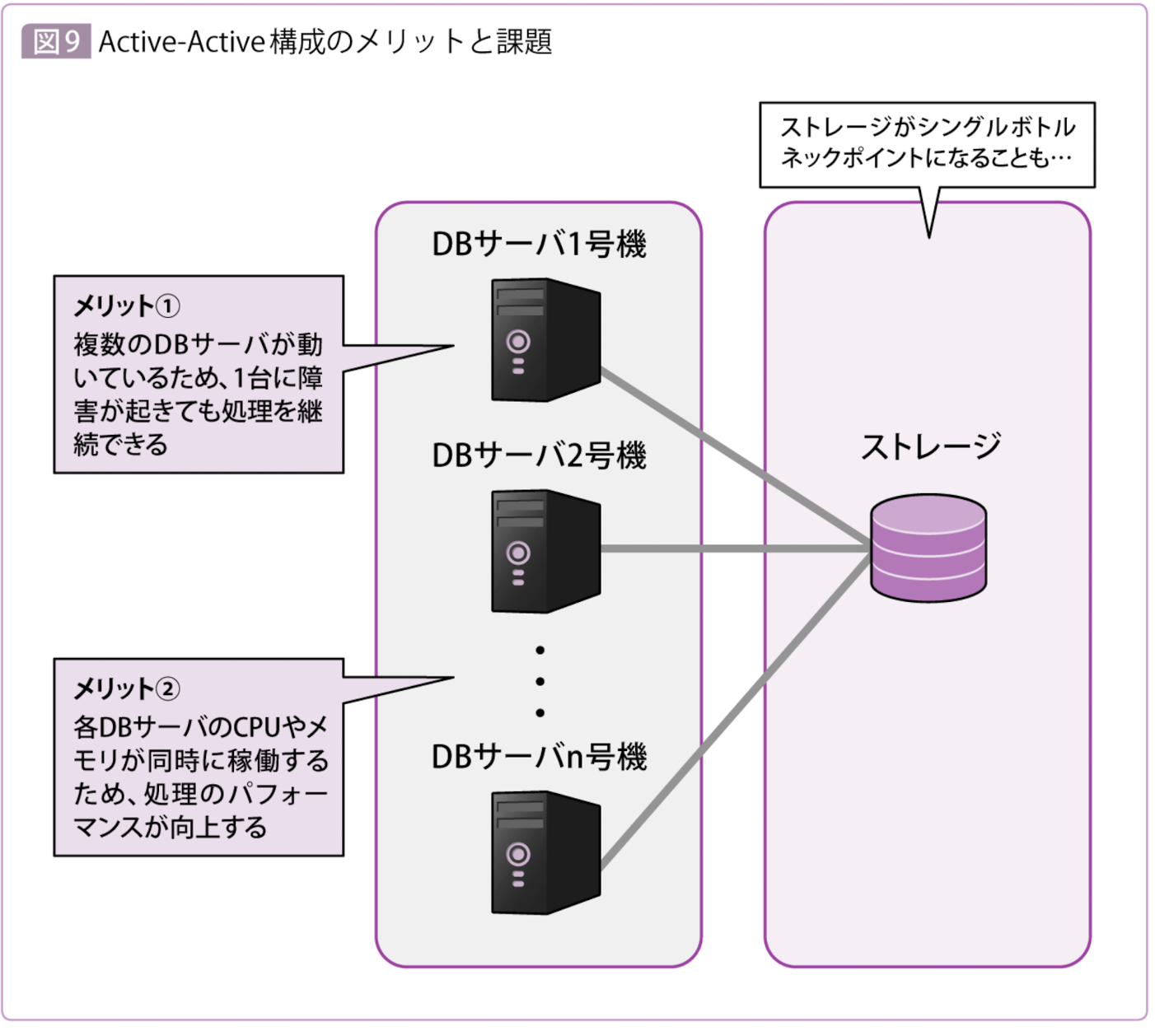
Active-Active構成のメリット
- ダウンタイム時間の短さ
Active-Activeの場合、複数のDBサーバが同時に動いているため、そのうちの1つがダウンして動作不能に陥ったとしても、残りのサーバが処理を継続することで、システム全体が停止することを防止できる
WebサーバやAPサーバのクラスタ化によって得られるメリットと同じ - パフォーマンスのよさ
DBサーバを増やしていくことで、同時に稼働するCPUやメモリが増加するため、パフォーマンスも向上が見込める。
ただし、ストレージ部分がボトルネックになることで、思ったほどの性能的なスケーラビリティが出ないこともよくある。
Active-Standbyの場合、Standby側のデータベースは普段使われず、現用系(Active側)に障害が起きたときだけ使われる。
そのため、どうしても切り替わるまでのタイムラグ(通常は数十秒〜数分)が生じ、その間はシステムのサービス継続が不可能な状態、いわゆる「ダウン」状態になる。
Active-Standby 構成の分類
Active-Standby構成は、さらに「Cold-Standby」と「Hot-Standby」に分類される。
- Cold-Standby
- 待機系のデータベースを普段は起動させておらず、現用系のデータベースがダウンした時点で待機系を起動するタイプのもの。
- Hot-Standby
- 普段から待機系のデータベースを起動させておくというもの。
当然ながら、切り替え時間はHot-Standbyのほうが短いが、そのぶんライセンス料が高く設定されている。
要するに、「常に2台のデータベースサーバを使っている」とみなされる。
しかし実際に稼働しているのは現用系の1台だけであるため、切り替え時間を短くするためだけにライセンス料を多く払うという点で、Hot-Standbyは、かなり「贅沢」な構成と言える(それでもActive-Activeに比べれば安い)
DBサーバーの冗長化(クラスタリング)で可用性が高い順番
可用性と性能のよい順に構成を並べると以下のようになる。(性能の観点において、Hot-StandbyとCold-Standbyの間に違いはない)
- Active-Active
- Active-Standby(Hot-Standby)
- Active-Standby(Cold-Standby)
これはそのままライセンス料の「値段順」でもある
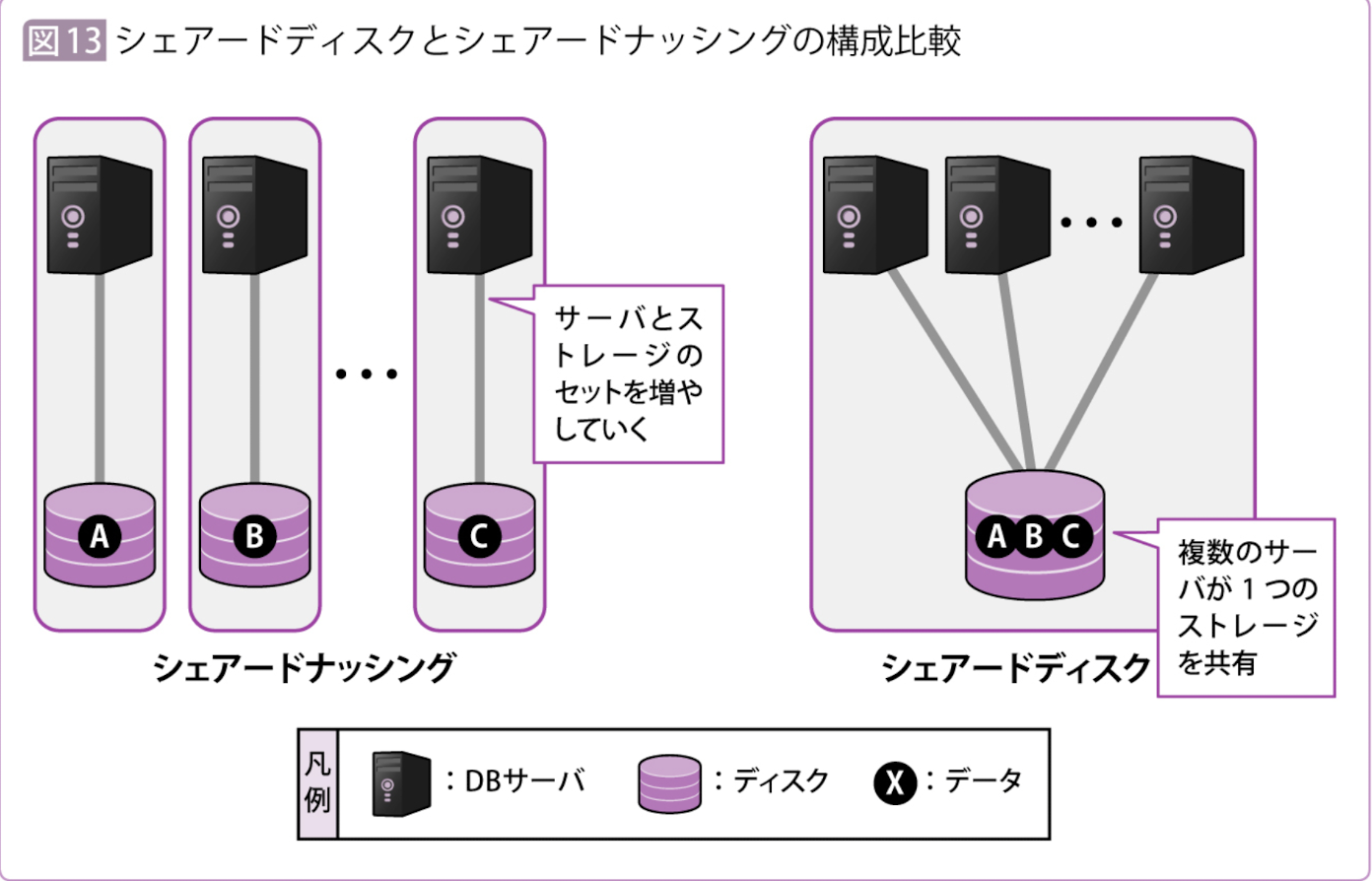
シェアードディスクとシェアードナッシング
Active-Active構成のDBMSでは、「ストレージ部分がボトルネックになることがある」
これは、複数のサーバが1つのディスク(ストレージ)を共有する構成になっているために起こる問題。
この複数のサーバが1つのディスクを使う構成のことをシェアードディスク型と呼ぶ
シェアードディスク型のActive-Active構成は、DBサーバを増やしていっても無限にスループットが向上するのではなく、どこかで頭打ちとなるポイントに達する。
これは、ストレージが共有リソースとなるため、簡単に増やすことができないことと、DBサーバ数が増えるほどDBサーバ間の情報共有のためのオーバーヘッドが大きくなっていくことが理由。
この欠点を克服するためのアーキテクチャとして考えられたのが、「シェアードナッシング(Shared Nothing)」と呼ばれる構成。
シェアードナッシングは、文字通り「何も共有していない」という意味で、ネットワーク以外のリソースをすべて分離する(=何も共有しない)やり方。
このアーキテクチャには、サーバとストレージのセットを増やせば、並列処理によって線形に性能が向上するというメリットがあります。
シェアードナッシング型では、DBサーバとストレージのセットで増やしていくことで、ストレージがシングルボトルネックポイントになることを防止している。
これによって、シェアードナッシングでは、このセットに線形比例する形でスループットが伸びていくという利点が得られる。
シェアードナッシングという構成については、以前から研究が行われていたが、Google社が劇的なやり方でその有効性を証明したことで、一気に実用の分野でも注目が集まった。
なおGoogle社は、自社が開発したシェアードナッシングの仕組みをシャーディング(Sharding)と呼んでおり、Google=大規模実装で有名にした
シェアードナッシング方式の利点は、「コストパフォーマンスのよさ」
シェアードディスク方式は、複雑な同期処理の仕組みが必要であるため、構築する難易度も高くなる。
一方シェアードナッシング方式は、同じ構成のデータベースを横に並べていくだけなので、仕組みがシンプルで、かつ原則としてデータベースのセット数に線形比例してスループットが伸びていく。
もっとも、こうしたわかりやすい長所の裏返しとして、シェアードナッシングにも欠点がある。
ディスク(ストレージ)を共有していないということは、つまり「それぞれのデータベースサーバが同じ1つのデータにアクセスできるわけではない」ということを意味する。
例えば、都道府県単位で「データベースサーバ+ストレージ」のセットを47個そろえたシェアードナッシングにおいては、東京都のデータを持つデータベースサーバがアクセスできるのは、当然ながら東京都のデータだけ。
同じことが、福岡県や北海道を担当するデータベースサーバについても言える。
たとえば都道府県別に保持されている人口のデータを合計して全国の人口を算出するような場合は、各セットから都道府県別の人口を集めてきて集計をする「まとめ」サーバが必要になったりする。
あるいは、東京都のDBサーバがダウンした際には、東京都のデータにアクセスできなくなる、といった問題も起こる。
この問題に対処するためには、1つのDBサーバがダウンした際には、他のDBサーバが処理を引き継ぐことができるようにするといった「カバーリング」の構成を考える必要がある(MySQLは「MySQL Cluster」というシェアードナッシング型のクラスタ構成をとることができるのですが、その場合はこういう引き継ぎ機能も利用できます)。こうしたケースの対処まで考えはじめると、アイデアとしてはシンプルに見えたシェアードナッシングも、見た目より複雑な仕組みであることがわかる。
シャーディング
データを水平分割して複数ノード(=シャード)に配置し、スループットと容量を水平スケールさせる手法(Shared Nothing の代表)
いつ使うか
- 単一ノードで CPU / IO / 接続数が頭打ち
- マルチテナント・地域・機能など自然な分割軸がある
- 書き込み負荷が高く、スケールアップのコスパが悪い
分割戦略(トレードオフまとめ)
| 戦略 | 仕組み | 強み | 弱み/注意 |
|---|---|---|---|
| レンジ型 | キー範囲で分割(例: 0–9999→A) | 範囲クエリに強い/実装が単純 | 偏りでホットシャード化しやすい(連番・時系列) |
| ハッシュ型 | キーをハッシュして分散 | 均等分散に強い/ホット抑制 | 範囲クエリが全シャード問合せになりがち |
| ディレクトリ型 | ルーティング表(キー→シャード) | 再配置が柔軟/例外対応に強い | メタストアのSPOF/整合性が課題 |
| 一貫性ハッシュ | リング+バーチャルノード | 追加/削除時の再配置が小さい | 実装・可視化がやや複雑 |
ルーティング設計
- アプリ内ルーティング:最速だが実装重め
- プロキシ/ミドルウェア:Vitess / Citus / ProxySQL など(透過的・1ホップ増)
- DAOガード:キー必須/クロスシャードSQL禁止などの規約で事故防止
トランザクションと整合性
- 単一シャード内:通常の ACID
- クロスシャード:
- 厳密整合:2PC / 合意(Paxos/Raft)
- 実務で多い:**Saga(補償)**で最終的整合性
- 集計は各シャードで部分集約 → 集約ノードでマージ(MapReduce的)
再シャーディング(リバランス)
- 事前に余白レンジやバーチャルノードを用意
- オンライン移行:コピー → CDC/ダブルライトで差分追随 → カットオーバー
- 失敗時のバックアウト手順を用意(切替前後の検証・戻し)
アンチパターン
- クロスシャード JOIN / ORDER BY の多用
- シャード無視の全表スキャン
- 「ユーザーID不要」等、キー非依存のAPI設計
運用で見る指標(例)
- キー偏り(スキュー)/ホットシャード発生率
- シャード別 QPS/レイテンシ/エラー率/再試行率
- リバランス時間・失敗率・欠落/重複検知(行数/ハッシュ比較)
DynamoDB との関係(補足)
- DynamoDB の**パーティション=マネージドな “シャード”**相当
- パーティションキー設計=シャーディング設計そのもの
- ホット回避:キーのランダマイズ(例:
tenantId#bucket(0..63))、時間+乱数、GSI で読取分散
実装順のおすすめ:アクセスパターン設計 → キー設計 → 分割戦略 → 再シャーディング手順。
まず「キー必須」を DAO で強制するだけで事故率が大きく下がります。
レプリケーション(複製)
Active-StandbyとActive-Activeによるクラスタ構成は、実は「サーバ部分は冗長化できても、ストレージ部分は冗長化されない、したがってデータが冗長化されない」という共通の欠点を抱えている。
すなわちストレージが壊れた時にはデータが失われるということ。
その堅牢さから災害対策(ディザスタリカバリ)のために利用されることもある。
もちろん、ストレージも内部のコンポーネントは冗長化されているのが普通だが、データセンター全体が地震で崩壊したり津波で流されたら終わり。
こういうケースに対応するためのクラスタ構成が「レプリケーション(複製)」
要するに、データベースサーバとストレージのセットを複数用意する。
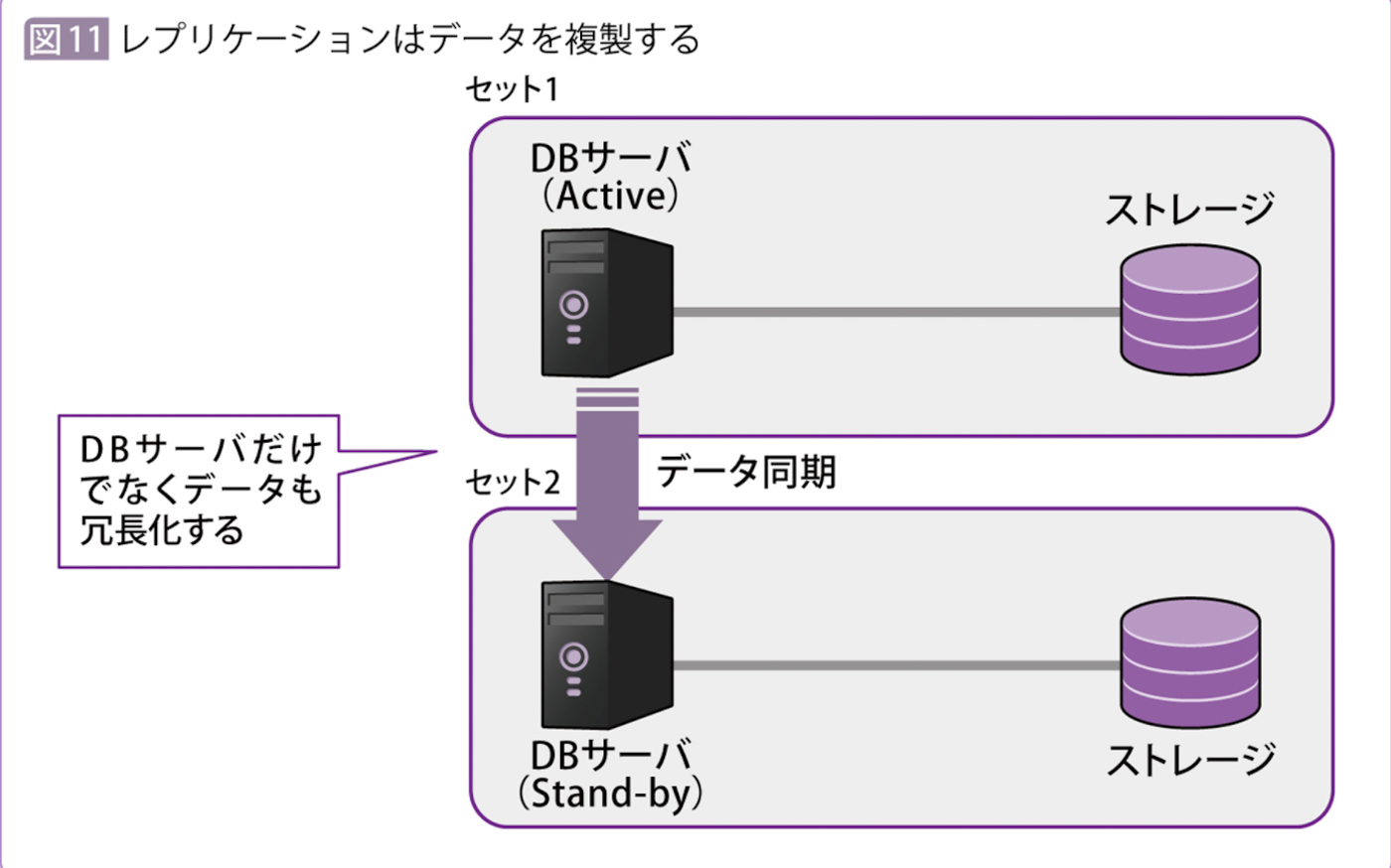
データを(距離的nも離れた)データベースにコピーする技術はレプリケーション以外にもある。
例えば遠隔地のデータベースに対してリモートでSQL文を発行してテーブルデータをコピーするといった方法で実装する手段もある。
この場合はそうした機能を開発側で実装する必要がある。
ディスクを冗長化するRAID(ハードディスクを冗長化)
ストレージ内部のコンポーネント(ほとんどの場合はハードディスク)を冗長化する技術をRAIDと呼ぶ。
RAIDにもいくつか種類があるのですが、基本的な考え方はクラスタリングと同じ「SPOF(単一障害点)をなくす」こと。
つまり、ディスクを並列的に並べていくことで1本のディスクが壊れただけではデータが失われないようにする。
レプリケーションの注意点
レプリケーションにおいて重要なポイントは、Active側のストレージ内のデータは常にユーザから更新されていること。
そのため、Standby側のデータにも更新を反映することで最新化していかないと(この最新化処理を「同期(sync)」と呼びます)Active側とのデータ整合性が取れなくなってしまう。
平たく言うと、Stand-by側のデータがどんどん古くなっていく。
例えばこの同期処理を1日に1回、夜間帯に行うとすれば、Active側のストレージが壊れた場合、最大で1日ぶんのデータ更新が消失することになる。
レプリケーションでは、Active側のDBサーバで行われた更新差分のデータを、ある程度の間隔でStand-by側DBサーバにも書き込んでいく。
そのとき、Stand-by側の更新を「どの程度厳密に行うか」ということと「パフォーマンス」の間にトレードオフの関係が生じる。
つまり、厳密にはStand-by側DBサーバ側でも書き込みが成功したことを確認した段階で、Active側の更新も完了とすることがデータ保護の観点では望ましいが、その確認処理をある程度省略することでパフォーマンスを向上させることもできる
(例えばOracleやDB2ではそうした同期処理のレベルをいくつか選択可能)
MySQLでは、同期する側の親(Active)のデータベースを「マスタ」、同期される側の子(Stand-by)のデータベースを「スレーブ」と呼ぶ。
つまり、「主人と奴隷の関係」
この呼び方はMySQLに限らず、レプリケーションにおいてはかなり一般的に使われる。
また、このマスタとスレーブによるレプリケーションを「マスタスレーブ方式」と呼ぶ。
このような呼び方があるのは、「両方がマスタ」という双方向レプリケーションの仕組みも存在するため(「マルチマスタ方式」と呼びます)
しかしかなり複雑な構成であまり見かけることはないため、まずはレプリケーションと言えば「マスタスレーブ方式」を念頭に置いてもらって良い。
100%の障害対策はできない
「クラスタも組んだし、レプリケーションも行ってるし、ここまでやれば障害対策はバッチリだ」と思っても確率的現象に100%という言葉は存在しない。
アーキテクチャ設計で尽くせるだけの手を尽くしたとしても、「全電源喪失」的な障害に遭遇する可能性はゼロにはならない。
もしそのような場合、すなわちすべてのデータが失われてしまったとしたら、残念ながら一時的なサービス停止は避けられない。
次に考えるべきは、「短期間での復旧」
復旧にかかる時間と社長が記者会見で頭を下げる時間は比例することが知られている。
そこで必要になってくるのが、「データのバックアップとリカバリ」