Amazon DynamoDB
Overview
Amazon DynamoDBは、フルマネージドサービス型の NoSQL データベースサービスであり、高速で予測可能なパフォーマンスと。シームレスな拡張性が特長。
※デフォルトでマルチAZになっている。
主な利用シーンには、低レイテンシーなデータアクセスが必要なアプリケーションや、大量のデータ利用やシステムに可用性・柔軟性を持たせたい場合などがある
RDB(リレーショナルデータベース)とNoSQLの違い
RDB(リレーショナルデータベース)とNoSQLにはメリットデメリットの点で大きな違いがある。
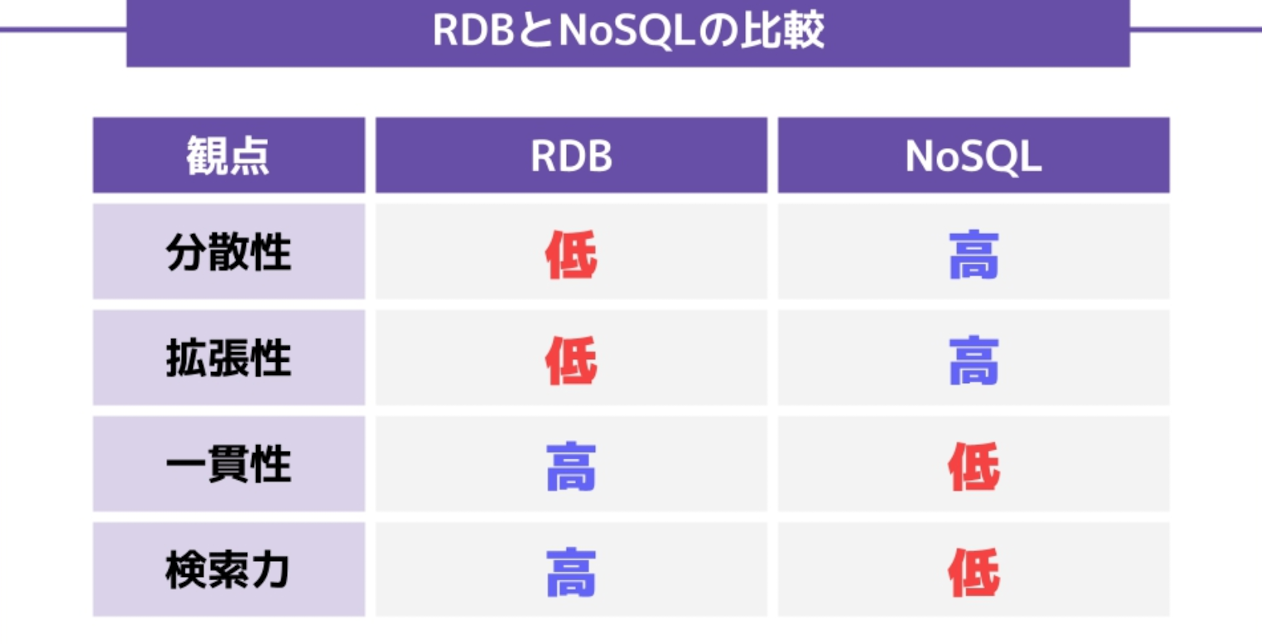
DynamoDBの特徴
DynamoDBには次のような特徴がある
- 高可用性(3つのAZでレプリケーションされます)
- データの格納と取得に高度に最適化
- 半構造化データを保存可能
- 1桁ミリ秒単位のレイテンシーにも対応可能
- データベースのサイズが縮小/拡大すると、自動的にスケーリングされる
その他、Lambdaとの相性がよいため、API Gateway + Lambdaと合わせて利用されることがよくある(サーバーレス開発によく使われる)
VPCからDynamoDBへの通信には、VPCエンドポイント(Gateway型)を使用することで、低コスト・安全な通信が可能。
dynamo初心者用
検索や集計は弱い(MySQLなどと併用する)
DynamoDBでは以前はプライマリキーを構成するキーをハッシュキー、レンジキーと呼んでいました。 しかし、最近ではAWSマネジメントコンソール上で下記のようにDynamoDBの以前で言うハッシュキー、レンジキーの表記が変更されていますので注意が必要です。
ハッシュキー→パーティションキー レンジキー→ソートキー
ハッシュキー → パーティションキー
レンジキー → ソートキー
にそれぞれ読み替える
データ型について(3種類しかないのは) CloudFormationから作成するときはこの3種類のデータ型しか使えないのかと混乱しました。しかし、そんなことはありません。これはプライマリキーとソートキーに使えるデータ型がこの3種類というだけです。プライマリキーとソートキー以外のカラムはCloudFormationに書かなくてよいので、レコード挿入時に自由なデータ型を使えばよいようです。
例
AttributeDefinitionsに書くのはパーティションキーとソートキーのみでよく、ほかは書いてはいけないというのが正解でした。テーブル作成時ではなく、レコード挿入時に自由にカラムを増やせます。
awslocal dynamodb create-table \
--table-name SessionCollection \
--attribute-definitions \
AttributeName=SessionId,AttributeType=S \
--key-schema AttributeName=SessionId,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1 \
--table-class STANDARD
DynamoDBの基礎
キャパシティユニット(Capacity Unit: CU)
キャパシティユニット(Capacity Unit: CU)とは DynamoDB の利用量(キャパシティ)を計算する単位のこと。
DynamoDB の利用量は項目を読み込んだ量と書き込んだ量で決まり、前者を読み込みキャパシティユニット(Read Capacity Unit: RCU)後者を書き込みキャパシティユニット(Write Capacity Unit: WCU)と呼ぶ。
ここで項目とは Relational Database(RDB)のレコードに相当するもの。
書き込みの場合は 1KB までのデータを 1 秒間に 1 回書き込むと 1WCU 消費される。
読み込みの場合は 4KB までのデータを 1 秒間に 1 回読み込むと 1RCU 消費される。
キャパシティモード
キャパシティモードとは作成したテーブルが処理できるリクエスト量を設定するもので、DynamoDB には オンデマンドモード と プロビジョニング済みモード の 2 つのキャパシティモードがある。
オンデマンドモードはキャパシティ設定を全て AWS にお任せするモードのことで、「どのくらいのリクエスト量が来るか想定できない」とか「数日間リクエストが来ない可能性がある」というようなユースケースに適している。
一方、プロビジョニング済みモードは設定したスループットを保証してくれるモードのことで、「具体的なリクエスト量が想定できる」ユースケースに適している。
例えば楽曲管理サービスの要件が「4KB までのデータを 1 秒間に 1000 回、強力な整合性のある読み込みで読み込めること」である場合、1000RCU を設定する。
パーティションとパーティションキー
DynamoDB がテーブルの項目を保持する領域を パーティション と呼ぶ。
またデータを割り当てるパーティションを決定するのが パーティションキーと呼ぶ。
パーティション
テーブルの内部を物理的に分割した「保存場所」
1つのテーブルはデータ量やスループットに応じて複数のパーティションに自動で分割される。
1つのパーティションの中には複数のアイテムが格納される。
パーティションキー
「このアイテムをどのパーティションに置くか」を決めるキー
値をハッシュ化して割り振る仕組み。
DynamoDBはKey-Valueストアなので、パーティションキー(Key)に対してValueが格納されます。
DynamoDBテーブルの項目を識別するプライマリーキーはシンプルキー(パーティションキーのみ)または複合キー(パーティションキーとソートキーの組み合わせ)で構成される。
ソートキーはシンプルキーでパーティションを一意に特定できない場合に使用する。
プライマリーキーだけで絞り切れない場合、プライマリーキー以外の属性を使ってデータに効率的にアクセスできるようセカンダリインデックスを作成する。
セカンダリインデックスには次の種類がある
- ローカルセカンダリインデックス(LSI)
- グローバルセカンダリインデックス(GSI)
なぜパーティションという概念が出てくるのか
DynamoDBの 設計思想(スケーラビリティ)に由来する
テーブルだけで足りないなら?
もし「テーブル = 1つの物理的な保存領域」で済ませていたら、データ量が増えるとその保存領域がすぐ限界になる。
RDBなら「シャーディング」や「レプリケーション」を人間がやって対応する必要があった。
DynamoDBの解決策
DynamoDBは「大規模でも自動でスケールする」ことが売り。
そのため、テーブル内部を パーティション という単位に自動分割し、データを複数サーバーに分散保存する。
-
パーティションキーをハッシュ化 → 「どのパーティションに入れるか」を決める
-
データ量やスループットが増えると → 自動的にパーティション数を増やす
-
例えでイメージ
- テーブル = 図書館
- パーティション = 本棚(内部の分割単位)
- パーティションキー = 本を「どの棚に置くか」を決めるルール(例: 著者名の頭文字)
もし本棚が1つしかなければ、蔵書が増えると物理的に入りきらない。 DynamoDBは 自動で棚を増やして本を分散配置 してくれる仕組みを持っている、だから「パーティション」という概念が登場するわけです。
つまりパーティションは、ユーザーが意識しなくても DynamoDB が裏で自動管理する「スケーリングのための物理分割」。 テーブル = 論理的な入れ物 パーティション = 物理的な入れ物
ソートキー
データをパーティション何のどこに配置するかを決定するのがソートキー。
ソートキーの値が同じデータはパーティション内で物理的に近い場所に配置される。
ソートキーを設定するかは任意となっている
プライマリキー
データを一意に識別するのがプライマリーキー。
プライマリーキーは「パーティションキー」または「パーティションキーとソートキーの複合キー」になる。
属性
属性とはRDBのカラム(列)に相当するもので、属性名と属性値で構成される。
項目内に定義可能な属性の数に制限はないが、1 項目内の全属性の属性名と属性値の合計サイズは 400KB 以下である必要がある
属性型
- Map
- JSONオブジェクト
- List
- JSON配列
属性に保存するデータについて
DynamoDBはJSON相当(Map/List)を格納可能だが、1アイテムの上限は400KB(属性名含む)。
大きなJSONはS3へ置き、DynamoDBには検索に必要な属性(キー、ステータス、タイムスタンプ等)のみを保存する S3+Index(DynamoDB)パターン を推奨。
柔軟な検索が必要な項目はトップレベル属性へ正規化し、GSIを活用する。
ローカルセカンダリインデックス(LSI)
ローカルセカンダリインデックスには次の特徴がある
- テーブル作成時にしか作成できない
- プライマリーキーが複合キーである必要がある
- パーティションキーをソートキー以外でのおこなうキーを別途設定できる
グローバルセカンダリインデックス(GSI)
テーブル作成時に設定したパーティションキー・ソートキーとは別のパーティションキー・ソートキーを設定する仕組みが グローバルセカンダリインデックス(GSI)
グローバルセカンダリインデックスには次の特徴がある。
- テーブル作成後も自由に追加・削除できる
- デフォルトで20個作成できる
- パーティションキーを別途作成できるイメージ(GSIがcである項目を検索したいときに便利)

GSI と LSI の違い
一番大きい違いは 強い結果整合性のサポート状
GSI はインデックス用に新たに指定したパーティションキーとソートキーで検索をするため、物理パーティションに囚われない検索が可能になる。
DynamoDB Accelerator(DAX)
DynamoDB Accelerator(DAX)とは、DynamoDBに特化したフルマネージド型高可用性インメモリキャッシュ。
主なユースケースとしては、高い読み取り負荷がかかるアプリケーション。
リアルタイム処理や読み取りが一時的に集中するようなアプリケーションが例に挙がる。
DAXは結果整合性のある読み取りワークロードの応答時間をミリ秒からマイクロ秒まで短縮できるため前述のようなアプリケーションに適している。
また、DynamoDBと互換性があるため、既存のアプリケーションに機能的な変更を加える必要がありません。 SAA試験では、DAXの読み取り操作に関する問題がよく出題されます。ユースケースまで理解しておくとよいでしょう。
DynamoDB Tips
DynamoDBに関連するtipsを記載
DynamoDB Local導入
localで構築したDynamoDBをGUIツールで見る
なぜDynamoDBを採用するのか
| 要件/事情 | なぜ DynamoDB か(機能/利点) |
|---|---|
| Lambda × バースト(同時並行が瞬間的に跳ねる) | コネクション不要のHTTP API型。RDSのような接続数上限/コネクションストームが起きにくい(RDSはProxy等が必要)。 |
| 低レイテンシでのKey-Value照会(トークン照合/失効確認) | 単一桁msの一貫した読み書き性能。主キーアクセス最適で、トークン→状態のO(1)参照に強い。 |
| スパイク/不規則な負荷 | **オンデマンド課金(Pay-per-request)**でアイドル時コスト最小化。予測困難でも自動スケール。 |
| トークンの時限性(自動期限切れ) | TTL属性で満了後の自動削除(GC不要)。運用が軽い。 |
| 同時更新の制御(二重発行/競合防止) | 条件付き書き込み(Conditional Writes)とトランザクションAPI(TransactWrite)で厳密な一意性や多キー整合を担保可能。 |
| マルチテナント/将来の多リージョン | グローバルテーブルでリージョン間レプリケーションをマネージド提供。DR/近接性の拡張が容易。 |
| イベント駆動(ブラックリスト化/監査ストリーム) | DynamoDB Streamsで変更イベントをLambdaへ。非同期失効・監査・キャッシュ無効化が組みやすい。 |
| 運用負荷を下げたい | フルマネージド(パッチ/容量/シャーディング/レプリカ管理不要)。運用Toilが小さい。 |
| セキュリティの一元化 | IAMでのきめ細かい権限、KMS暗号化、VPCエンドポイントで閉域接続。 |
RDS と DynamoDB の棲み分け
- RDS:リレーション/複雑なJOIN、厳密なSQL集計、トランザクションを跨いだ一貫性の強い業務処理、BI用途。
- DynamoDB:トークン照合・セッション/リフレッシュトークンの管理、レート制御、IDマッピング、カウンタなど主キー照会中心の高速KV。
認証領域では「読み書きが細かく大量・スパイクする」「主キー照会が中心」「期限と整合チェック」が多く、DynamoDB の特性に合致。
典型的なデータモデル(例)
- PK:
USER#<userId> - SK:
RT#<jti>(リフレッシュトークンID) - 属性:
expiresAt(TTL対象),status(active/revoked),clientId,issuedAt,ip,uaなど - GSI1(
jti直引き用・失効即時参照):PK = JTI#<jti>,SK = USER#<userId> - TTL:
expiresAtをTTL属性に設定(満了後自動削除)
アクセスパターン
- 検証:
GetItem(PK=USER#u1, SK=RT#jti)またはQuery GSI1 (JTI#jti) - 失効:
Update ... SET status='revoked'(Conditionで多重失効防止)→ Streamsで監査/キャッシュ無効化 - ローテーション:
TransactWriteで新発行+旧失効を原子的に
コスト/パフォーマンス観点のポイント
- オンデマンドならアイドル時の固定費が小さい
- 接続プール不要で、Lambdaのスケールに比例して自然に伸びる(RDSは接続上限とスロットリングがネックになりがち)
- 1アイテム
≤400KBの上限はあるが、トークン用途は十分小さい。
リスク/注意
- クエリは主キー/GSI設計次第。入れ子JSONへの柔軟クエリは不得手 → 必要な検索キーはトップレベルへ正規化。
- ホットパーティション回避のため、
userId偏りがある場合はバケット化(例:USER#<userId>#<rand(0..63)>)を検討。