Database
Overview
Databaseに関する情報をまとめたセクション。
データベースとDBMSは違う。
- データベース
- データの集積を指す論理的概念
- DBMS
- データベースを実装したソフトウェア
データベース設計を制するものはシステム開発を指す。
それはシステムがデータのフォーマットに合わせて作られるから
※システムに合わせてデータを作るのではない。
データベースから情報を取得する場合は、膨大なデータをただ眺めていても出てこない。
これは「どのような時期によく買っているか」「どのような種類の商品をよく買っているか」といった観点(文脈)による分析が必要になる。
したがって、情報とはデータと文脈を合成して生まれてくるものと言って良い。
情報とは、データから、ある文脈なり観点なりに従って集約したり加工したりしたものを指すため。
参考
学習効率を上げるためのバックエンドのデータベース基礎知識
瞬殺でDBを使って何かしたいとき
DockerでサクッとDBからER図を作成する
データベース設計の際に気をつけていること
SQLスキーマを改善する
DB設計をするときに考えるステップ
イミュータブルデータモデル
エンティティで考える
データベースの基本概念
DBの種類
- RDBMSとNoSQLの違い
- データベース設計の基礎
DBの設計
SQLの基本
- SELECT文、INSERT文、UPDATE文
- JOINとサブクエリ
トランザクションとACID特性
- トランザクションの定義
- ACID特性の詳細
インデックスとパフォーマンス
- インデックスの種類と使用法
- クエリ最適化
データベース管理
- ユーザー管理とセキュリティ
- バックアップとリカバリー
分散データベース
- シャーディングとレプリケーション
- CAP定理
クラウドデータベース
- クラウドデータベースの利点と課題
- 主なサービスプロバイダー
データベースの監視とチューニング
- パフォーマンスモニタリングツール
- チューニング手法
データベースのセキュリティ
- データ暗号化
- アクセス制御
最新トレンド
- ビッグデータとデータベース
- 新しいデータベース技術の紹介
DBセクションの各ディレクトリ名を英語で表現するには、以下のようになります:
- Database Basics - データベースの基本概念
- SQL Basics - SQLの基本
- Transactions and ACID - トランザクションとACID特性
- Indexes and Performance - インデックスとパフォーマンス
- Database Management - データベース管理
- Distributed Databases - 分散データベース
- Cloud Databases - クラウドデータベース
- Monitoring and Tuning - データベースの監視とチューニング
- Database Security - データベースのセキュリティ
- Latest Trends - 最新トレンド
これらをディレクトリ名として使用してください。
DBに求める機能と要件
データベースを選択するときに検討するべき要件を整理
データ量を考慮する
データベースに保存するデータ量がどれぐらいの規模なのかを検討する必要があります。
データ量の単位はデータサイズでも表現できますし、データ件数でも表現できます。たとえば、数万件規模のデータ量なのか、数百万件規模のデータ量なのか、数億件規模のデータ量なのかによっても変わるため、データ量を整理しておくことは重要。
データ増減パターンを考慮する
データ量がある程度一定に保たれるのか、大きく増減するのかという観点での検討も重要
たとえば、何かしらのマスタデータであればデータ量が大きく変化することはありません。
また週次でデータが1件ずつ増える場合も一年間で52件しか増えませんので、大きく変化することはありません。
しかし、購入履歴データであれば、ユーザー数と購入件数によって大きく増えていく可能性があります。このように、データ増減パターン(とくに増える場合)という観点で整理することは重要です。
保持期間を考慮する
保持しているデータをいつまで保持するのかを整理する必要がある。
たとえば、直近1年のデータのみ必要で、それ以降は削除できるケースであれば、1年間の最大のデータ量を前提に設計できます。
この場合、データに対してTTL(TimeToLive:有効期限)を設定できるツールやサービスを利用することで、不要となったデータを効率的に削除できます。
ほかには、アプリケーションとしては必要がなくても、第三者機関の監査ポリシーなどにより、数年間残しておく必要があるケースもあります。
アクセスパターンを考慮するc
アクセスパターンとは具体的には参照(検索も含む)・追加・更新・削除などがある。
データベースはアプリケーションからどのアクセスパターンを受け入れるのか、そしてそれぞれの利用回数に傾向はあるのかも検討する必要があります。
具体的に例を挙げると、一度追加されたらその後は参照が多くなるパターン(ReadHeavyと言います)もあれば、追加されたデータの参照は比較的少なく新規の追加が多くなるパターン(WriteHeavyとも言う)もあります。
書籍サービスなどではアクセスパターンとして参照パターンが多い。
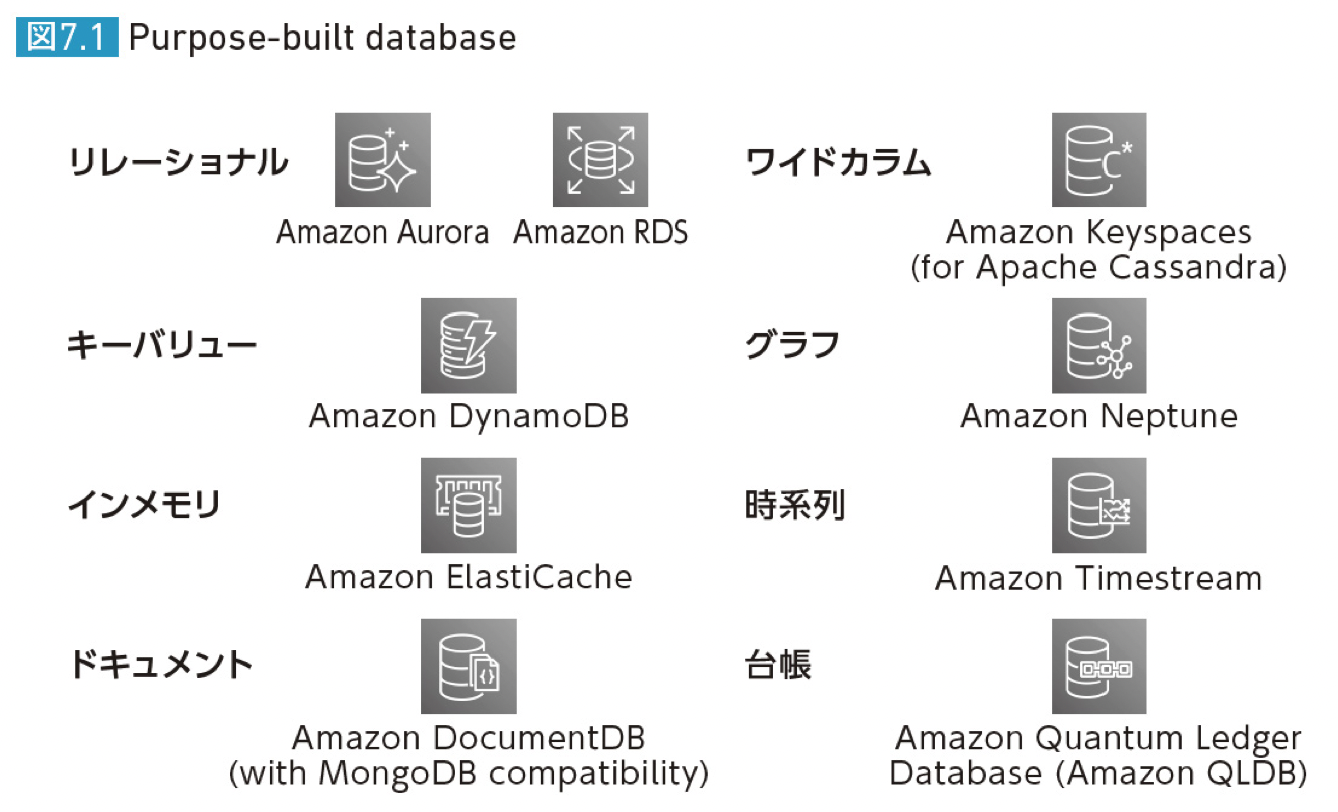
形式を考慮する
保存するデータの種類や形式を整理することも重要。
AWSでは以下の形式で整理している。
- リレーション
- キーバリュー
- インメモリ
- ドキュメント
- ワイドカラム
- グラフ
- 時系列
- 台帳
DBの要件を整理後
データベースはアプリケーションで実現したい要件に最適だからという理由で選択するべき。
こういった考え方をPurpose built databaseと言います。
そして、AWSにはPurpose built databaseを実現するために、多くのデータベースサービスがあります。
触る時に考えること
- 本番を触る時はすべてエビデンスをとれ(スクショなど)
- 何をしたのかしっかりと伝えられること。そのためのエビデンス
- CRUDの内のC(create)U(update)D(delete)をする前には必ずselectをしろ
- indexは大体どこのSQLでも単一の値にはインデックスが貼られている。 → しかし複数の値での検索時はインデックスが貼られていないため検索回数が多いのは検討をしインデックスを貼る。
DB設計の時の考え方
どうせ最初からパーフェクトなテーブル設計はできない。
最初は完璧になんて不可能なので、ある程度考え、実装し、間違っていればまたやり直す。を繰り返すことが一番の近道。
あ、どうせ変化していくものな�ので完璧を求めすぎないこともポイント。
DB 検索は 1 回で終わらせる。
DBにアクセスする部分は一度の検索で終わらせるべき。(処理が重いため)
ただ副問い合わせなどをするとパフォーマンスはどちらが上なのかは知りたい
データベース設計の際に気を付けること
- 制約をつける
データベース設計において重要なのはいかにして不整合を起こさないようにするか。
「データを引いてみたら関連先のレコードが無くなっている」、「このレコードはユーザーごとに1つだけ持つはずだけど、2レコードある」など。 不整合は往々にして発生する。
データを挿入・更新・削除してもよいかのチェックはアプリケーションレベルで防ぐだけではなく、可能ならばデータベースレベルでも行う。
そのために、以下制約をつける努力をする。
- 外部キー制約をつける
- �ユニークキー制約をつける
Table Entity関係を書く
ER図を書いていくことになる(デファクトスタンダード)
table 命名規則
一時的なレコードと永続化が必要なレコードを同じテーブルには入れない
構造が同じでも意味が違うデータは分けて管理すべきだと、私は思います。 その方がレコードの行数も少なく抑えられて、注文テーブルを引くコストが下がります。
SQL設計
DB・テーブル設計のプラクティス
SQLアンチパターンを避けるためのチェックリスト①(DB論理設計編)
パスワード保存について
データベースに生の(平文の)パスワードを保存するのは情報セキュリティの観点から望ましくない。
その代わりにパスワードのハッシュ値を(あるいはダイジェスト)と呼ばれる値をデータベースに保存するのが定石
アプリケーションからのDB基本利用法
アプリケーションからDBにアクセスするためにはデータベース固有のプロトコルを用いてアクセスする必要があり、各DB向けに実装されているドライバーを使う。 一方アプリケーション側から呼び出す接続コードは、データベースドライバーの実装に依存し��ない汎用的なAPI
DBバックアップについて
ダンプのファイル量が多いと時間がかかる。
そのため、その際にデータの書き換えがあるとデータの相互性が失われる。
そのためデータのバックアップを取得するときはDBを停止して行うべき
DB種類
- キーバリューストア memcachedやRedis
DB分割構成
Webアプリケーションの規模が大きくなると応答速度の低下が問題になることがあり、ボトルネックとなるのはDBアクセスに関する部分。
そういった問題を解決し、複数のDBを利用するgemパッケージとしてOctopusなどがあったがRails6.0からはRails標準機能として複数DBへ対応した。
しかし、実際に複数DBとして望まれるケースで多いのは書き込みと読み込みの負荷を軽減させるために書き込む用のデータベースと、そのデータを同期した読み取り用データベースに分割する構成。
書き込み用データベースをプライマリーDB レプリケートした読み取り専用データベースをレプリカDB
上記の構成の場合、レプリカDBへ直接マイグレーションの適用やデータの書き込みは行わない(RailsではレプリカDBであると明示するため database.yml にreplicaを指定する)
実運用ではレプリカDBへの接続は参照権限のみのユーザで接続するのが望ましい。
リードレプリカ(read replica)
リーどレプリカとは、DBの負荷分散のために作成される参照専用の複製。 データの更新&追加は行わず検索や読みこみのみを行う。
データベースのスキーマ
- MySQLではDBとスキーマは同じと思って良い
- PostgreSQLではデータベースがあってその下にスキーマが存在する(デフォルトでpublicスキーマが作成される)
リレーションの読み込み方
Eager Loading 訳:熱望的なローディング or 積極的なリレーションシップ
Eager Loadingでは、2つのテーブルのデータを1度に取得する(関連のも)
Eager Loadingを使うと、クエリの発行回数を減らすことができるので、いわゆる「N+1問題」の回避策として用いられる。
Lazy Loading 訳:怠惰なローディング
リレーションの際、親テーブルからデータA取得する。次に子テーブルから(便宜上、親テーブルのidを持っているもの)データAのidに関連するデータを取得する。
というように2回に分けてデータを取得すること。
N+1問題とは?
クエリの発行回数が過剰に増えて、サーバーサイドでタイムアウトエラーなどの不具合を起こしてしまう現象のこと
データベーススキーマ設計の完全ガイド
- ブルのROW_FORMATがDynamic(Barracuda)であることを確認する
- MySQL5.6まではデフォルトのフォーマットはCompact(Antelope)でしたが、これは1レコードあたり8KBまでしかデータを入れることができません。 テキスト型を使うと8KB制限を突破してしまうこともあるため、テーブルのフォーマットがDynamic(Barracuda)であることを確認します。
- 整数値を入れる場合はint型かbigint型を使う
- float型は使わない
- 精度のトラブルに巻き込まれたくないためfloatは使いません。多くの場合、doubleかdecimalで問題ありません。 金額情報など、精度を求められる小数値にはdecimalを使う doubleも小数点以下の精度に悩まされることがあります。金額を扱う、精度が必要な計算は必ずDecimalを利用します。
- 日付を入れる場合はDATE型を使う
- 商品のお届け日など、日付を入れる場合はDatetimeやTimestamp型ではなくDATE型を使うようにします。DatetimeやTimestampはタイムゾ�ーンの影響を受けるためです。
- JSON型を使ったら負け
郵便番号や電話番号のnumberかstringかの悩み
- 算術計算の対象ではないのでstringにする。
命名規則
-
大文字を利用しない。 テーブル名、カラム名ともに大文字を利用しない。 (DBにより大文字小文字を区別するもの、しないものなどがあるため小文字で統一を図る)
-
複数単語の連携はスネークケース テーブル名、カラム名ともにスネークケースを利用する。 キャメルケース、キャメルバックはNG。
DB・テーブル設計のベストプラクティス
テーブル 複数形 vs 単数形
実際のところWEB系のフレームワークなどは複数形を好むため、複数形のテーブル名に慣れ親しんでいる人は多い。
空文字 or NULL
空文字だと、電話番号を持っているが電話番号がない。というようなよくわからない事情がでる。
そのため持っていないのであれば NULL にした方がいい。
データが存在しないのならば、素直にNULLを入れるべきです。
OAuth2.0のユーザーテーブル設計
エンティティ保存方法を考える
このエンティティの識別子の生成方法には様々な種類がありますが,大きく分けて永続化前に生成する早期生成と永続化後に生成する遅延生成の2種類に分けられます
id 設計
主キーは検索のキーとして利用されたり、他の関係に参照のために格納されたりする確率が高いため、できる限りデータ量の小さい方がよい。
よって複合キーはあまり適さない。
ナチュラルキーとサロゲートキーはどちらがいいのか
ナチュラルキー(自然キー)
キーそのものに意味が含まれているキーで、業務的にそのテーブルをユニークにするキーをナチュラルキーという。
要は入力データ自体をPKとして場合、PKはナチュラルキーとなる。
たとえば、以下のようなテーブル構成の場合のユーザーテーブルのユーザーコードのように、それだけで意味のわかるキーがPKとなっている場合、ナチュラルキーと言います。
サロゲートキー(代理キー)
サロゲートキーは、テーブル内のレコードを一意に識別するために使用される人工的なキーであり、通常はシステムによって生成される。 これはテーブル内の他のデータとは独立している。
サロゲートキーの特徴
-
システム生成
- サロゲートキーはデータベースシステムが生成する一意の識別子。
- 一般的には整数のシーケンスが使用される。
-
意味を持たない
- サロゲートキーは実際のビジネスデータに関連する意味を持たず、純粋に一意性のために使用される。
-
安定��性
- データの変更や統合が発生しても、サロゲートキーは変更されることがない。
- 例: オートインクリメントの整数ID(id)、UUIDなど。
-
テーブル間の依存関係が薄くなる
-
アプリケーションの画面間引き継ぎ情報や実装などを統一できる
-
複合主キーのテーブルに比べSQLが簡潔になる
-
業務上は意味のないキーを持つので、容量を余分に使う
サロゲートキーはアンチパターンとも言われている
(アンチパターンとも言われますが)サロゲートキーとしてidなどの自動採番の数値を主キーとする設計も現場では多く(ORMを使っているケースだったり、セカンダリインデックスにプライマリーキーが含まれることによるインデックスサイズの増加を懸念したり)その様な場合に主キーの値の変更はそこまであるケースではないため、カスケード更新自体が登場する機会は少ない。
サロゲートキーをプライマリキーとして使用することは、データベース設計のベストプラクティスの一部であり、多くのシナリオで推奨されます。一方で、ナチュラルキーを使用する場合も、その属性が安定して変更されないものである場合には有効です。状況に応じて適切なキーを選択することが重要で�す。
uuidで使う
メリット
- users/1とかでプライマリキーを連番にすると推測されやすい。スクレイピングされやすいのを回避できる(書いてて思ったけど、idをencryptすればいいじゃね?CFCみたいな)
デメリット
- insertが完了するまでidがわからない。
- DBクライアントによっては処理が落ちる(MySQL (InnoDB) ではプライマリキーにランダムな値を用いるとINSERTの効率が落ちてしまいます)
処理に時間がかかる場合、先にidだけ返して永続化処理は非同期に実施することがときどきありますよね(画像アップロードとか) こういう時もDB側での採番だと実際DBにinsertするまではidが確定しないので、本当は今この瞬間にinsertする必要がなくても採番するためだけにDBとのI/Oが発生することになります。同時にたくさんのファイルをたくさんのユーザーがアップロードするよ!みたいな機能を作りたい時にちょっとパフォーマンスが心配ですよね
プライマリキーにULIDを使う
外部キー制約
参照されるのが 親テーブル
参照するのが 子テーブル
リレーションシップの種類
-
依存リレーションシップ 子テーブルの存在が親に依存している場合
-
非依存リレーションシップ 子テーブルの存在が親に依存していない場合
多対多
多対多の関係の場合にどうテーブル設計をすれば良いかわからなくなってしまいがち。
そうなんです。多対多の関係の場合、どう頑張っても良い設計にならないのです。 ですのでそもそも多対多の関係にならないような設計が必要で、その解消方法は中間テーブルを用意し1対多の関係になるように設計することが必要
論理削除の可否
twadaさんに語ってもらった 論理削除はアンチパターンのひとつだが割とよくある設計。
レコードを消したい。でも消したくないみたいな時に削除フラグ項目を設け、レコードをDELETEするのではなく削除フラグをUPDATEして、SELECTの条件で削除フラグがTRUEなら取得しないようにするやつです。
頻繁に復活させたり、レコード数が少ないテーブルに設けるのであれば検討の余地はありますが、基本的には論理削除を用いないほうが良いでしょう。
内部結合と外部結合の違い
DBパフォーマンス関連
チューニング
速度低下の原因はSQLが内部的にどのような処理を行っているかを表示させるexplainで見ることができる。
- SQLが遅い場合は、explainである程度遅い原因を確認できる
- 件数が多いテーブルで重い処理が実行されているときは要注意
- なるべくインデックスを使って処理されるよう、order byなどの指定を変えてみる
ORDER BYで起こること
ORDER BY 使うと全部並べ替えようとする。
ORDER BY使わずにSELECTするのは速いけど、実際の業務では現実的ではないため使用しない。
そのためインデックス使うのが一般的
インデックスはソートされているようなものなので、インデックスがあればORDER BYはインデックスを元に行われる
LEFT JOIN で起こること
LEFT JOINする時、大抵はONでJOINの結合条件を設定する。
FROMに指定した テーブルA のレコードが10000件、JOINに指定したテーブルBのレコードが1000件あった場合
テーブルA のレコードの件数分、テーブルB の対象レコードを探す処理が必要になる
これは、最悪の場合10_000_000レコード分の処理になる (10_000 * 1_000) JOINは掛け合わせなので元になる�情報が大きければ大きいほど、その結果が膨れ上がることになる 一般的にJOIN遅いって言われているのは、これのせい
DBに値を入れる基準
データベースに値を入れておくと外部キーを貼れるというメリットがある。 システムでの重要ポイントになるような「状態を表す値」を定義する場合に、リストにない値が入ってしまえば混乱しか産まないので、たとえ数個しかなくても外部キー制約のためにテーブルを立てることは、よく行います。
都道府県の場合も、内部的に「都道府県ID」で管理するなら、データベースへの投入はほぼ必須となります。単にリストとして使う場合は、どちらでも構いません(DBのないところで運用できる、というのがDB外で管理するメリットとはなります)
DBを作るときのTips
インデックス
データベースにおけるインデックスとは、目的のレコードを効率よく取得するための「索引」のこと。
インデックスは、データベースがデータを効率的に探索できるようにするデータ構造です。データベースがクエリを実行する際に、インデックスがあると、データベースはテーブルの全行をスキャンする代わりにインデックスを使用して必要なデータを迅速に見つけることができます。これはとくに、大量のデータを扱うテーブルでその効果を発揮します。
インデックスの効果 検索性能の向上: 特定の条件でデータを検索するクエリがある場合、インデックスを利用することで検索操作が高速になります。 データの一意性の保証: 一意のインデックスを作成することで、指定されたカラムの組み合わせに重複がないことを保証できます。これは、データの整合性を維持するのに役立ちます。 注意点 インデックスのオーバーヘッド: インデックスは検索性能を向上させますが、データの挿入、更新、削除の操作においては、インデックスの再構築が必要になるため、これらの操作を遅くする可能性があります。そのため、インデックスは慎重に使用する必要があります。 インデックスの選択: インデックスを作成するカラムは慎重に選択する必要があります。頻繁に検索条件として使用されるカラムや、テーブルの大部分のクエリで使用されるカラムにインデックスを設定することが一般的です。 結論として、:user_product_id, :event, :transaction_idのカラムに対するインデックスの作成は、これらのカラムを含むクエリのパフォーマンスを大幅に改善しますが、インデックスの管理には注意が必要です。
複合インデックス(コンポジット索引)
コネクションプール
コネクションプールは、データベース接続を効率的に管理するためのテクニック。
アプリケーションがデータベースに接続するたびに、新しい接続を作成する代わりに、コネクションプールから既存の接続を取得して再利用できる。
これにより、接続と切断のたびに発生するオーバーヘッドを削減し、システムのパフォーマンスを向上させることが可能となる。
コネクションプールの利点
- 効率性: 接続の確立には時間がかかるため、コネクションプールを使用することで、そのオーバーヘッドを減らすことができる。
- スケーラビリティ: 同時に多数のクライアントがデータベースに接続する場合でも、コネクションプールを通じて接続数を制御することで、サーバーの過負荷を防ぐことができる。
- リソースの最適化: コネクションプールによって接続が再利用されるため、リソースの使用が最適化される。
コネクションプールとサーバーレス実行環境の問題(Lambda)
AWS Lambdaのようなサーバーレス環境では、コネクションプールを使用する際には注意が必要。
Lambda関数はイベントごとにトリガーされるステートレスなコンテナーで実行されるため、Lambda関数の実行が終了するとコンテナーとそのリソースが廃棄される可能性もある。
つまり、関数がトリガーされるたびに新しいコネクションプールが作成され、既存のプールが再利用されない可能性もある。
そのため、Lambdaでコネクションプールを使用する場合には、以下の点に留意する必要があります:
- コールドスタート問題: Lambda関数が初めて実行されるとき、新しい接続をプールに追加する必要があるため、レスポンスが遅れる可能性もある。
- コネクション数の管理: Lambda関数がスケールアウトすると、同時に多数のコネクションがデータベースに張られることがあるため、データベースの接続数の上限に達するリスクもある。
これらの問題を回避するためには、AWSが提供するRDS ProxyやAurora Serverlessなどのサービスを利用する、または、Lambda関数の実行コンテキストを再利用することでコネクションプールを効率的に管理する方法を検討する必要があります。それにより、Lambda関数が実行されるたびに新しいデータベース接続を作成するのではなく、コンテナーの寿命を通じて接続を再利用することが可能。
コネクションプールは通常、アプリケーションサーバー上で動作しているプール管理ライブラリまたはミドルウェアによって管理されます。これはアプリケーションのプロセスメモリ内に存在し、アプリケーションが稼働している間は維持されます。
コネクションプールの管理
コネクションプールを管理する際には以下の要素が重要です:
- ライフサイクル: プールされた接続は生成、使用、そして再利用または廃棄というライフサイクルを持つ。
- 数の管理: プールは同時に開くことができる接続数を制御する。
- 状態の監視: 接�続の健全性を確認し、必要に応じて接続を再生成する。
アプリケーションメモリとコネクションプール
コネクションプールは、アプリケーションが使用するメモリスペースに保持されます。アプリケーションが起動すると、プール管理システムは一定数のデータベース接続を確立し、これらの接続をアプリケーションが要求するたびに割り当て、解放された後は再利用できます。
コネクションプールとORM
コネクションプールの概念はORM(Object-Relational Mapping)固有のものではありません。ORMは、オブジェクト指向プログラミングと関係データベース管理システム(RDBMS)の間の橋渡しをするものであり、データベース操作をオブジェクト指向の視点で行えるようにするものです。
しかし、多くのORMライブラリにはコネクションプール機能が組み込まれています。例えば、TypeORMのようなORMは内部的にコネクションプールを使用してデータベース接続を管理でき、アプリケーションのパフォーマンス向上に寄与します。プール�の具体的な管理はORMの内部で抽象化されており、開発者はプールのパラメータを設定するだけでよく、個々の接続について細かく管理する必要はありません。
サーバレス環境でのコネクションプール
サーバレス環境(例えばAWS Lambda)では、各関数の実行インスタンスが独自の実行コンテキストを持つため、従来のコネクションプールの概念に適用するのは難しい場合があります。Lambda関数が新しい実行コンテキストで実行されるたびに、新しいコネクションプールが作成される可能性があるためです。しかし、AWS Lambdaでは関数の実行間でコンテキストを再利用できるため、一度確立されたデータベース接続を再利用することが可能です。ただし、これには適切なコネクション数の管理やライフサイクルの管理が必要になります。
パーティション
パーティショニングは、大量のデータを持つテーブルを小さな部分に分割するデータベースのテクニック
これにより、クエリのパフォーマンスが向上し、データの管理が容易になることが多い。
パーティショニングは、とくに大��規模なデータセットを効率的に処理する必要があるときに役立つ。
データベースのパーティショニング戦略を検討する際は、以下の点を考慮することが重要。
- パーティションの種類: レンジ(範囲)、リスト、ハッシュなど、さまざまなパーティションタイプがある。
- パーティションのキー: どのカラムを基にパーティションを分割するか。
- クエリのパフォーマンス: 特定のクエリがパーティション化されたデータにどのように影響するか。
- メンテナンスの容易性: パーティション化によりメンテナンスが複雑にならないか。
また、実際にパーティショニングを行う前に、データの成長予測、クエリパターン、アプリケーションの要件を詳細に分析することが不可欠です。
デメリット
パーティショニングには制約もあり、とくに外部キー制約を持つテーブルにパーティションを適用する場合、データベースシステムによってはサポートされていないか、制限がある可能性。
たとえば、PostgreSQLでは外部キー制約を持つテーブルのパーティショニングは制限されている。
外部キーを持つテーブルにパーティションを適用する際は、データ整合性を保ちつつパフォーマンスを改善するための工夫が必要になる。
パーティション種類
いくつかある。
- LISTパーティショニング
- RANGEパーティショニング(履歴が永遠に重なるテーブルの場合はパーティションを設定してあげる。月毎など)
- HASHパーティショニング
適用方法
排他制御(楽観ロック・悲観ロック)の基礎
排他制御の長さ
排他制御している時間が長ければ長いほど、システムの利便性が下がってしまう。そのため、不都合や不整合が発生しない範囲で可能な限り短くすることが鉄則。
排他制御の方式
- 楽観ロック(楽観的排他制御)
- 悲観ロック(悲観的排他制御)
楽観ロック(楽観的排他制御)
楽観ロックとは、めったなことでは他者との同時更新は起きないであろう、という楽観的な前提の排他制御。
データそのものに対してロックは行わずに、更新対象のデータがデータ取得時と同じ状態であることを確認してから更新することで、データの整合性を保証する方式。
楽観ロックを使用する場合は、更新対象のデータがデータ取得時と同じ状態であることを判断するために、Versionを管理するためのカラム(Versionカラム)を用意する。
更新時の条件として、データ取得時のVersionとデータ更新時のVersionを同じとすることで、データの整合性を保証できる。