AWS Glue
Overview
AWS Glueは、データレイク上のデータを分析するためにデータの前処理をおこなうサービス。
データレイクとは(湖)
音声・動画・ログデータといったさまざまな媒体から生成されるデータを整形・変換される前の状態で保存できる、データの「貯蔵庫」
データレイクを活用することで、大量のデータが保存でき、必要なときに必要なデータを取得して活用することが可能になる。
また、生データを分析対象のデータにするためには、データの前処理としてETL処理をおこなう。
AWSだとS3が該当する。
- Extract(抽出)
- Transform(変換)
- Load(格納) ETLは上記の頭文字をつなげたもの。
Extract(抽出)
分析に必要なデータを抽出する。
不要なデータは抽出しないため分析処理を効率よく進めることができる。
Transform(変換)
データを書き出しやすいように、一定の規則に従いデータを加工・変換する。
必要に応じて重複値の除去やデータのグループ化などを行う。
Load(格納)
加工・変換したデータを、分析実行するデータウェアハウスなどのデータストアにデータを格納する。
Glueの特徴
Glueには次のような特徴があります。
- サーバーレスで利用可能
- フルマネージドサービス
- セキュアな暗号化に対応
- データをETLの処理するコードを自動的に生成
- 他のAWSサービスと容易に連携が可能
Glueの機能
Glueには大きく分けて5つの機能が備わっている。
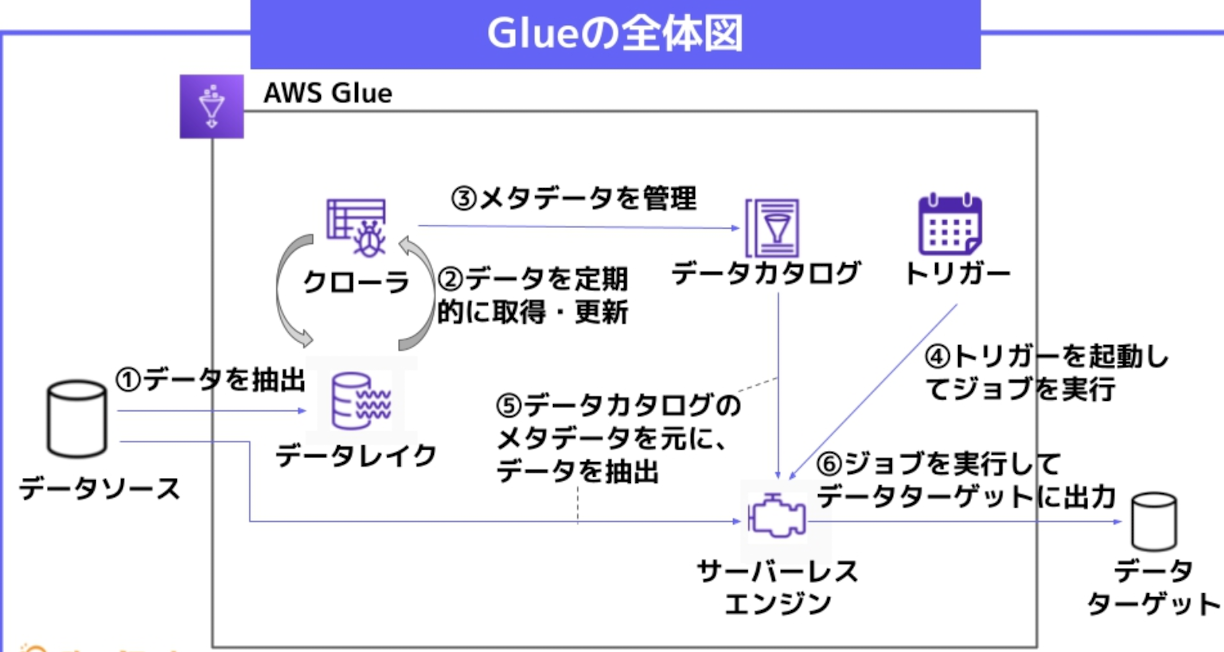
クローラー
データレイクを定期的に巡回し、メタデータを取得・保存するプログラム。
取得したメタデータをデータカタログに登録・更新する。
メタデータとは、データそのものではなく、データに関する属性などの付帯情報を記述したデータ。たとえば、文書データであればタイトルや作成者名、保存場所などのことです。
データカタログ
クローラーが取得したメタデータを保持する場所。
データカタログをもとに、必要なデータを取得して分析処理をおこなう。
ジョブ
ETL処理を実行するための処理単位。
ジ��ョブの種類には、Python ShellとApache Sparkがある。
Glueが自動生成したコードや自分自身で作成したコード、既存のコード(オンプレミスで動作していたものなど)を実行してデータ変換とターゲットへの格納をおこないます。
トリガー
トリガーを起動することで、ジョブとクローラーを実行できる。
ワークフロー
複数のジョブやクローラーの実行とモニタリングを管理します。データ抽出からジョブを実行したデータ出力まで一連の処理を自動化することが可能。
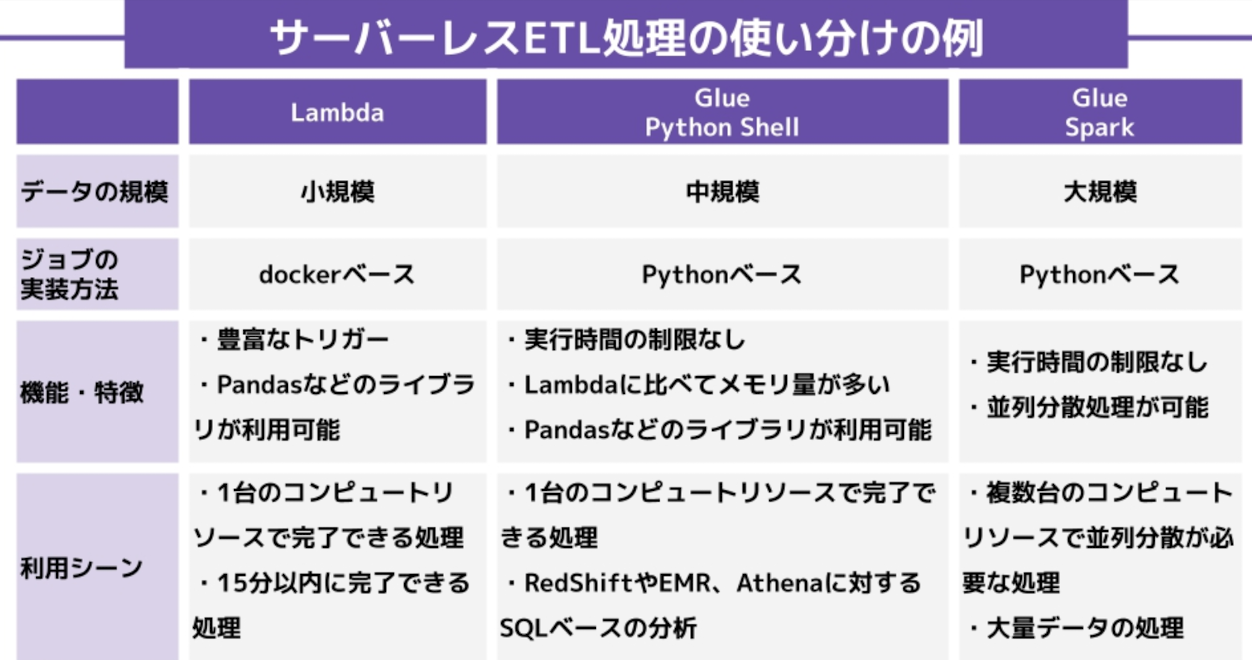
サーバーレスETL処理の使い分けの例
サーバーレスでETL処理をおこなう場合、Glue以外の選択肢としてLambdaを使用するケースがある。
どちらのサービスを選ぶかは、データの規模やETL処理の目的、ジョブの実装方法などによって使い分ける必要がある。
それぞれの機能・特徴や利用シーンを次の表にまとめています。