Clean Architecture(クリーンアーキテクチャー)
概要
クリーンアーキテクチャはRobert C. Martin(Uncle Bob)が2012年に提唱した、DBやフレークワークからの独立性を確保するためのアーキテクチャである
前節のレイヤードアーキテクチャが提案されて以降も、ヘキサゴナルアーキテクチャ、オニオンアーキテクチャなどが提案されてき
た。
これらのアーキテクチャで用いられる用語は異なるが、目指すところは同じであるとクリーンアーキテクチャ(The Clean Architecture)では述べている。
関心の分離が共通しているという話。
これらのアーキテクチャはど��れも細部は異なるけれども、とてもよく似ている。これらはいずれも同じ目的を持っている。関心の分離だ。これらはいずれも、ソフトウェアをレイヤーに分けることによって、関心の分離を達成する。どれも、最低ひとつは、ビジネスルールのためのレイヤーと、インターフェイスのためのレイヤーがある。
有名な図についての解説
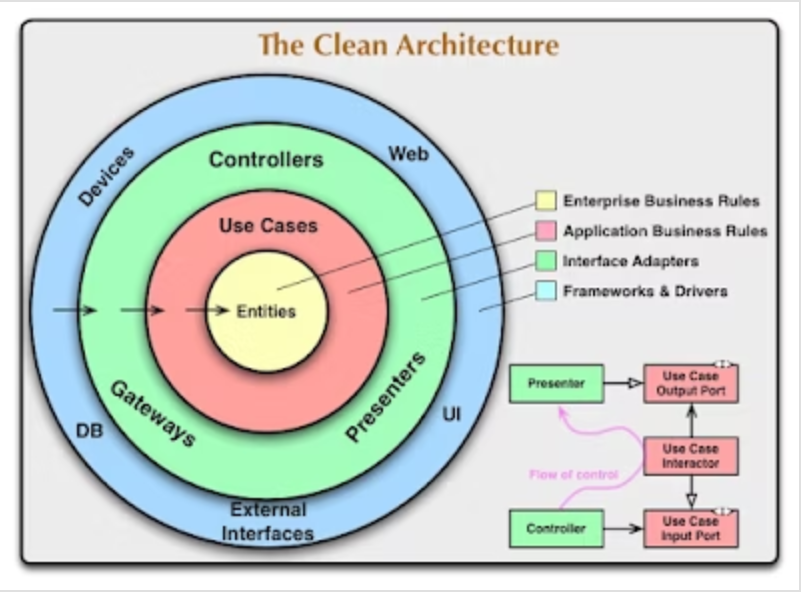
一般的な図やアーキテクチャの表現では、インフラストラクチャ層は円の外側に配置されるが、これは上位のレイヤー(ドメイン層やアプリケーション層)がインフラストラクチャ層に依存していることを示すため。
これは、上位のレイヤーが下位のレイヤーに依存するという依存関係を視覚的に表現するためのもの
ただし、これはあくまで一般的な表現であり、図やアーキテクチャの具体的な表現方法は組織やプロジェクトによって異なる場合がある。
重要なのは各レイヤーが適切な責務を持ち、依存関係が適切に管理されていること。
クリーンアーキテクチャが実現したい�こと
クリーンアーキテクチャは、以下のような多くの目標や原則に基づいている。
これらは、ソフトウェアをメンテナンスしやすく、拡張しやすく、そしてフレームワークに依存しない形で設計するために重要。
-
関心の分離(Separation of Concerns): システムの異なる部分が独立していることを保証し、変更が他の部分に影響を与えにくくする。
-
プラットフォームからの独立: アプリケーションのビジネスルールがUI、データベース、フレームワークなどの外部要素から独立していること。
-
テスト可能性(Testability): ビジネスルールを外部のUI、データベース、ウェブサーバーなどに依存せずにテストできる。
-
UIとビジネスロジックの分離: UIが変更されてもビジネスロジックに影響を与えず、逆もまた同様。
-
データベースの独立: ビジネスルールが特定のデータベースの実装に依存しない。
-
外部エージェントからの独立: 外部のライブラリやフレームワークの変更がビジネスルールに影響を与えないようにする。
-
交換可能なコンポーネント: システムのコンポーネントを容易に交換できるようにするため、設計をモジュラーに保つ。
-
複数のクライアント: システムがさまざまな種類のクライアントで動作することを可能にする(ウェブ、モバイル、APIなど)。
-
ドメインルールの集中: ドメインルールやビジネスロジックが一箇所に集中しているため、ドメインの変更が容易になる。
-
スケーラビリティ: アーキテクチャがスケールアップやスケールアウトに対応しやすい設計になっている。
-
持続可能な開発速度: 初期の開発速度だけでなく、プロジェクトが成熟するにつれて維持される開発速度。
-
リスクの軽減: 一部のコンポーネントが失敗した場合や技術的負債が積み上がっても、システム全体が破綻しないようにリスクを分散する。
これらの目標を達成するために、クリーンアーキテクチャでは、ソフトウェアを複数のレイヤーに分割し、各レイヤーが特定の役割と責任を持つように設計します。依存関係のルール(依存性の逆転の原則を含む)は、これらのレイヤー間の関係を整理し、システムの柔軟性と耐久性を向上させるのに役立ちます。
基本的なディレクトリ構成
クリーンアーキテクチャーを採用する際の一般的なディレクトリ構成は以下らしい。
.
├── application/
│ ├── services/
│ ├── interfaces/
│ ├── dtos/
│ └── mappers/
├── domain/
│ ├── entities/
│ ├── value_objects/
│ ├── repositories/
│ └── use_cases/
│ ├── interfaces/
│ └── implementations/
├── infrastructure/
│ ├── persistence/
│ │ ├── repositories/
│ │ └── models/
│ ├── web/
│ │ ├── controllers/
│ │ └── views/
│ ├── cli/
│ └── external_services/
└── presentation/
├── cli/
├── web/ # このコンテキストでは、webは従来のウェブベースのUIを指します。これはHTML、CSS、JavaScriptなどを使用してブラウザで実行されるページやアプリケーションを意味し、通常、サーバーから直接レンダリングされるビューやテンプレートを含みます。
└── api/ # apiは、RESTful APIやGraphQL APIのような、HTTPリクエストを介してクライアントとサーバー間でデータを交換するインターフェイスを指します。APIは通常、フロントエンドフレームワーク(例:Next.js)またはモバイルアプリなどのバッ�クエンドと連携するためのエンドポイントを提供します。
- domain: これは、アプリケーションのビジネスロジックが含まれる中心的なレイヤーです。ここには、アプリケーションが扱うエンティティ、バリューオブジェクト、リポジトリのインターフェース、およびユースケースが含まれます。
- application: アプリケーションのユースケースをオーケストレーションするサービス層であり、ドメインレイヤーとインフラストラクチャレイヤーの間のメディエーターとして機能します。
- infrastructure: データベース、ウェブフレームワーク、外部APIとの統合など、外部の世界との接続ポイントを提供します。
- presentation: エンドユーザーに対するインターフェースを提供します。これにはウェブアプリケーションのUI、APIエンドポイント、CLIなどが含まれます。
クリーンアーキテクチャーの実装は、採用する技術スタックやチームの好みによっても変わってきます。したがって、上記のディレクトリ構造はあくまで一例であり、プロジェクトのニーズに応じて調整することが重要です。実装の詳細や、特定のプログラミング言語やフレームワークに対するクリーンアーキテクチャの適用方法については、さらにリサーチする必要があります。
大事なこと
クリーンアーキテクチャーでは、依存関係が外側へ向かってのみ発生することが原則。
つまり、コードは**内側のレイヤー(より高レベルのポリシーを持つ)に依存することはできますが、外側のレイヤー(より詳細な実装を持つ)に依存することはできません。**これを「依存関係の逆転の原則(Dependency Inversion Principle)」と呼びます。
例(内側のレイヤー(より高レベルのポリシーを持つ)に依存することはできますが、外側のレイヤー(より詳細な実装を持つ)に依存することはできません。)
// Domain Layer (内側レイヤー)
// user.entity.ts
export class User {
constructor(public id: string, public name: string) {}
}
// user.repository.ts
export interface UserRepository {
findById(userId: string): User | undefined;
save(user: User): void;
}
// Application Layer
// UserService(アプリケーションレイヤー)はUserRepositoryインターフェース(ドメインレイヤー)に依存していますが、具体的なSqlUserRepository実装(インフラストラクチャレイヤー)には依存していません。依存関係はインターフェースを通じて逆転しています。
// user.service.ts
import { UserRepository } from "../domain/user.repository";
import { User } from "../domain/user.entity";
export class UserService {
constructor(private userRepository: UserRepository) {}
public getUser(userId: string): User | undefined {
return this.userRepository.findById(userId);
}
public createUser(user: User): void {
this.userRepository.save(user);
}
}
// Infrastructure Layer (外側レイヤー)
// user.repository.impl.ts
import { User } from "../domain/user.entity";
import { UserRepository } from "../domain/user.repository";
export class SqlUserRepository implements UserRepository {
findById(userId: string): User | undefined {
// Implement the logic to find a user by ID using SQL
}
save(user: User): void {
// Implement the logic to save a user using SQL
}
}
// プレゼンテーションレイヤー(コントローラー)
// プレゼンテーションレイヤーであるuser.controller.tsは、ユーザーを取得するためにUserServiceに依存しています。ここでの依存もインターフェースを介しており、アプリケーションレイヤーからドメインレイヤーへと内側に向かっています。
// user.controller.ts
import { UserService } from "../application/user.service";
import { SqlUserRepository } from "../infrastructure/user.repository.impl";
const userRepository = new SqlUserRepository();
const userService = new UserService(userRepository);
export function getUserEndpoint(userId: string): User | undefined {
return userService.getUser(userId);
}
代表的な上位のレイヤーから下位のレイヤー
上位のレイヤーから下位のレイヤーを並べる一般的な例を示します。ただし、具体的なアプリケーションやアーキテクチャによって異なる場合もあることをご了承ください。
- ドメイン層(Domain Layer): ビジネスルールやドメインモデルを表現し、ビジネスロジックを実装します。
- アプリケーション層(Application Layer): ユースケース(Use Case)やアプリケーションサービスを実装します。ドメイン層を呼び出してビジネスロジックを実行します。
- インターフェース層(Interface Layer): ユーザーインターフェースや外部システムとのやり取りを担当します。Web APIやUIコンポーネントなどが含まれます。
- インフラストラクチャ層(Infrastructure Layer): データベースや外部API、ファイルシステムなどの外部リソースとのやり取りを行います。
このような並び順になりますが、実際のアプリケーションによってはさらに細かなレイヤーや構造が存在する場合もあります。重要なのは、依存関係が上位のレイヤーから下位のレイヤーに向かっていることであり、上位のレイヤーは下位のレイヤーに依存せず、下位のレイヤーは上位のレイヤーに依存することです。これにより、各レイヤーが疎結合であり、変更やテストが容易になります。
実現できること
クリーンアーキテクチャはソフトウェアをレイヤーに分離することで関心事の分離を実現し以下の特性を持ったシステムを生み出す。
- フレームワーク非依存:システムをフレームワークの制約で縛るのではなく、フレームワークをツールとして使用する
- テスト可能:ビジネスルールはUIやDB、サーバー、その他の外部要素がなくてもテストできる
- UI非依存:UIはシステムの他の部分を変更することなく、簡単に変更できる
- データベース非依存:ビジネスルールはDBに束縛されていない
- 外部エージェント非依存:ビジネスルールは外界のインターフェースについて何も知らない
重要なこと
重要なのは依存関係が上位のレイヤーから下位のレイヤーに向かっていることであり、上位のレイヤーは下位のレイヤーに依存せず、下位のレイヤーは上位のレイヤーに依存すること。
高レベルモジュール、低レベルモジュール
クリーンアーキテクチャや他の多くのアーキテクチャパターンにおいて、「高レベル」とはビジネスロジックやアプリケーションのポリシーを表し、「低レベル」とはより具体的な詳細、たとえばデータへのアクセス方法やUIの操作などを指します。
クリーンアーキテクチャでは、外側のレイヤー(例:UI、インフラストラクチャ)は内側のレイヤー(例:アプリケーション、ドメイン)に依存しています。しかし、依存性の逆転の原則によって、内側のレイヤーが外側のレイヤーの実装の詳細には依存しません。代わりに、外側のレイヤーが内側のレイヤーの定義した抽象化(インターフェースや抽象クラスなど)に依存します。
この原則を適用することによって、高レベルのポリシーが低レベルの詳細によって影響を受けなくなり、システムの変更や進化がより柔軟になります。低レベルの実装を変更しても、高レベルのポリシーに影響を与えないようにするためです。
例として、application レイヤーではビジネスのユースケースを扱い(高レベル)、domain レイヤーではビジネスロジックやエンティティ(ビジネスオブジェクト)を扱います(低レベル)。しかし、application レイヤーは domain レイヤーの実装詳細には依存せず、必要なインターフェースに対する依存だけを持ちます。これにより、どのようにデータが永続化されるか(たとえば、データベース、APIコールなど)は domain レイヤーではなく、それを実装する infrastructure レイヤーの詳細になります。
設計中に崩れ始める兆候
クリーンアーキテクチャでは依存関係の方向が内側から外側に向かうように設計することが推奨されている。
一般的に、上位のレイヤーは下位のレイヤーに依存することは許容されますが、下位のレイヤーは上位のレイヤーに依存しないようにすることが理想的。
したがって、Usecase同士が互いに依存し合うのは、クリーンアーキテクチャにおいては望ましくありません。Usecase同士の依存関係が発生する場合、それは設計上の問題の兆候となる可能性があります。
Usecase同士の依存関係が生じる場合、それらの依存関係を再評価して、より適切な設計を考えることをオススメ。
たとえば、依存関係を持つUsecaseを統合する新しいUsecaseを作成する、依存関係を共通の抽象インターフェースに置き換える、または依存関係を外部のフレームワークやライブラリに移譲するなどのアプローチが考えられます。
依存関係を整理し、クリーンアーキテクチャの原則に従った設計を行うことで、コードのテスト容易性、保守性、拡張性を向上させることができます。
種類
同じ考え方を持ったアーキテクチャに「オニオンアーキテクチャ、ヘキサゴナルアーキテクチャ、レイヤードアーキテクチャ」等がありますが、クリーンアーキテクチャはこれらの概念を統合する��為に作られたアーキテクチャです。
ドメイン(Domain)
Domainはビジネス側で定義するもっとも重要な定義。 ビジネス側というのは、たとえばソフトウェア開発については素人だけど、そのソフトウェアを使う分野に長けている人のことを指します。 銀行システムを作るとしたら、ビジネス側の人は倍返しが好きそうな銀行の行員など。 DDDの思想として、Domainは開発者側だけではなくビジネス側の人間にも理解できるように設計するというのがある